Иерархия реагирования на внешний стимул: от бездумного к осмысленному
Актуальная версия Beast Инструкция по работе с Beast
Если посмотреть максимально обобщенно на эволюцию адаптивности живых существ, то можно выделить направление, в контексте которого происходит постепенное усложнение реагирования и повышение качества адаптации: постепенный переход от ситуативной реакции к прогностической. Имея опыт выполненных в определенных условиях ответных действий с оцененным эффектом, становится возможным использовать все более эволюционно совершенные функции анализа и ассоциативного поиска оптимальной реакции для текущей ситуации. Чем больше накопленная опытом база данных, тем более удачно можно подобрать решение. Работа таких функций и демонстрирует интеллект, обеспечивая эффект их действий и оптимальность. Значимость эффекта в искусственных системах задает разработчик при проектировании и оператор при обучении, а в живых биологических системах значения эффективности вытекают из сформированной в процессе эволюции системы гомеостаза и адаптационных механизмов поддержания оптимального уровня критически важных жизненных параметров. Однако биологические живые организмы, кроме этого, в разной степени способны определять цель решения проблемной ситуации, сопровождаемую субъективными переживаниями (самоощущением), что наиболее ярко выражено у высших позвоночных, в особенности у человека. Зачем же для решения тривиальной задачи прогностического реагирования потребовалось вводить эти особенности и в чем их функциональность? Чтобы ответить на этот вопрос, нужно проследить стадии эволюционного усложнения адаптивности.
Если рассматривать этапы зарождения эффекта самоощущения, то следует начать с появления механизма удержания образа стимула его закольцовкой через гиппокамп. Благодаря этому стало возможным долговременно сохранять новую реакцию уже без многократных повторений, так как закольцованный образ продолжает воздействовать на психику, как если бы он был реально активным и этого времени достаточно для закрепления связей. Другая отправная точка, это возможность оценивать выполненную реакцию по достижению цели: в простейшем случае если сравнить состояние жизненных параметров до и после реакции, то в случае их улучшения, реакцию можно считать успешной, а при ухудшении соответственно не успешной. Это в свою очередь сделало возможным развитие механизмов корректировки реакции, вплоть до блокировки в случае, если она будет признана неприемлемой. Если представить это в виде диалога Оператора и Beast, то получается взаимная адаптация: Оператор провоцирует своими стимулами ответы Beast, меняя его внутреннее состояние, Beast аналогично провоцирует на ответы Оператора, так же меняя его состояние.
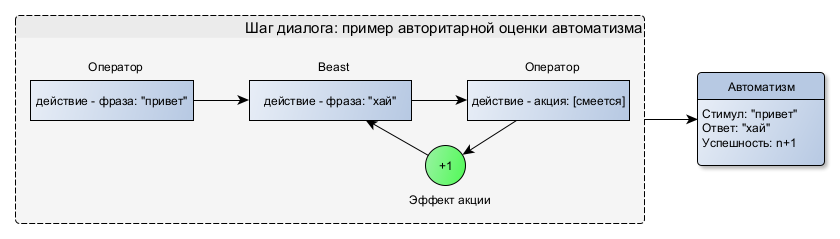
Попытка переоценки автоматизма происходит при каждой его активации. Новый стимул, следующий за выполненным действием автоматизма, является для него условием оценки, если имеет гомеостатический эффект, способный изменить текущее состояние жизненных параметров для срабатывания маркера «Стало лучше/Стало хуже». Новая оценка успешности складывается с текущей. Если Успешность становится отрицательной, автоматизм блокируется. В результате, чем больше было положительных оценок при активации автоматизма, тем он более устойчив: потребуется много негативных оценок или одна критически негативная, чтобы его заблокировать. Этим обеспечивается консерватизм блокировки автоматизма.
Так появился новый тип реакции – автоматизм, который в отличие от рефлекса способен модифицироваться в течении жизни одной особи, что означает переход эволюции адаптивности на качественно более высокий уровень. В простейшем случае автоматизм возникает путем «клонирования» рефлекторного действия потому, что это самый простой и очевидный способ редактирования рефлекторной базы. Пусть рефлекторное действие невозможно изменить ввиду отсутствия у рефлекса механизмов модификации, но можно скопировать его в автоматизме и уже там модифицировать, например, усилить или ослабить. При этом, чтобы не было взаимной конкуренции, автоматизм блокирует выполнение рефлекса в такой же ситуации, то есть имеет приоритет выполнения: рефлекс выполняется только если нет автоматизма для этих условий. Такая блокировка нижестоящего слоя вышестоящим, как более новым - широко распространенное явление в природной нейросети, позволяющая эволюционным развитием наращивать функционал не меняя старого.
И вот здесь уже появляется простейшее самоощущение на уровне плохая/хорошая реакция потому, что адаптивные действия обретают конкретную значимость, позволяя прогностически видеть, переживать ожидание последствий. Неадекватные действия ведут в конечном итоге к смерти, адекватные препятствуют этому. И если мы говорим об эволюции адаптивности в течении жизни одной особи, то понятие "значимость" для нее выражено намного более объективно, чем для существа со строго рефлекторным типом реагирования, для которого смерть не является концом существования, а наоборот, важным элементом оценки успешности/не успешности адаптации в течении жизни многих особей.
Теперь уже не только случайные мутации, передаваемые через поколения, стали формировать индивидуальную базу реагирования, но и личный опыт с прогнозами последствий, который нельзя передать по наследству через геном, а только путем обучения от родителя к детенышу. Процесс выделения из окружающего авторитета (импринтинг) для отзеркаливания его действий как учительских, доступен уже на самых ранних стадиях развития, но с разной степенью эффективности. Однако при таком бездумном копировании чужих действий неизбежно возникают ситуации, когда с одним пусковым стимулом связывается несколько автоматизмов, или когда один автоматизм может запускаться несколькими пусковыми стимулами. Это можно проиллюстрировать на примере авторитарного обучения Beast на третьей стадии, с имитацией ситуации, когда он «наблюдает» чужие диалоги и копирует их себе как руководство к действию.
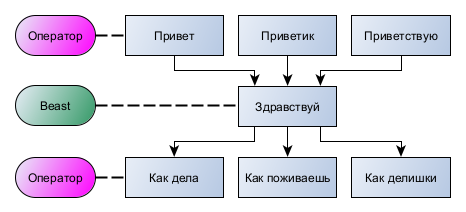
Beast исправно фиксировал различные варианты стимулов и ответов от Оператора (Учителя) и получил в итоге несколько вариантов реагирования на один и тот же стимул.
Простейшим решением проблемы, когда на один стимул есть несколько автоматизмов, где один назначен штатным (привычно выполняемым по умолчанию), будет переоценка штатного при каждой его активации: вдруг среди «запасных» найдется более подходящий, ведь при авторитарном обучении постоянно добавляются новые варианты.
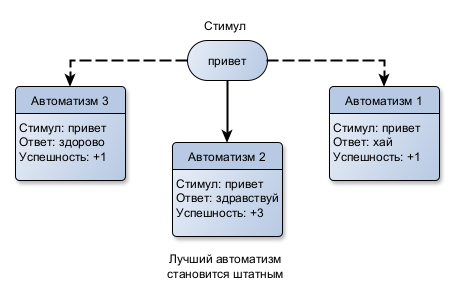
Если сравнить свойство «Успешность» у всех автоматизмов, привязанных к одному стимулу, то может оказаться, что при очередном отзеркаливании добавился более удачный. Тогда можно сделать его штатным, а текущий штатный понизить в статусе, переведя на «скамейку запасных». При каждой удачной активации автоматизма, если сработал маркер «стало лучше», свойство «Успешность» увеличивается, а не при неудачной (стало хуже) уменьшается.
Дальнейшее развитие механизма удержания образа привело к тому, что кратковременная оперативная память о ситуации становится долговременной постоянной – возникает эпизодическая память (ЭП). Это дало существенное преимущество: стало возможным, обращаясь к прошлому опыту, прогнозировать развитие ситуации. Теперь при каждом новом стимуле кроме оценки успешности выполненного автоматизма происходит запись кадров ЭП в формате Стимул – Ответ – Эффект, сохраняющих историю процесса адаптации. Группа кадров ЭП разделенная специальным маркером прерывания («пустой кадр») образует цепочку, обозначаемую как Правило реагирования. Прерывание означает потерю внимания к последовательности эпизодов событий. На примитивном уровне осмысления, причинно-следственная связь отслеживается только внутри цепочки, то есть, пока нет прерывания, все события, начиная от последнего прерывания, считаются причинно-связанными. Рассмотрим это на примере проекта Beast:
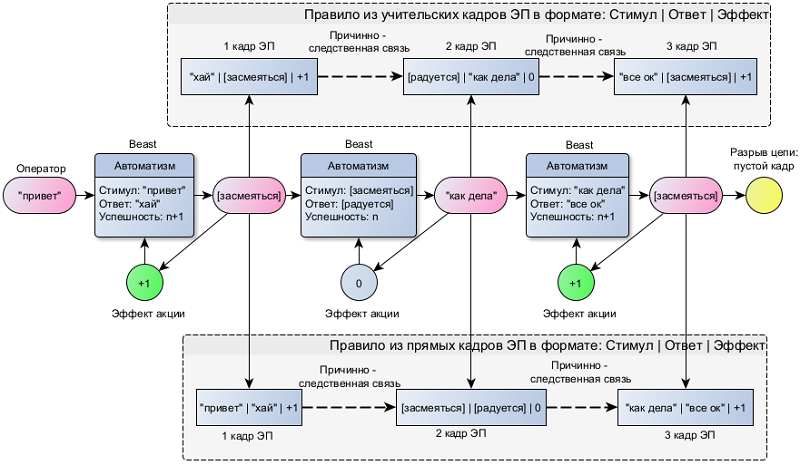
При каждом новом стимуле, начиная с 4 стадии развития Beast, записывается кадр ЭП в формате Стимул – Ответ – Эффект. Где в качестве стимула выступает предыдущее действие, выполненное Оператором или Beast. Это приводит к тому, что образуются 2 типа правил: Прямое – как ответил Beast на стимул от Оператора, и Учительское – как ответил Оператор на стимул от Beast. Ведь диалог это непрерывная цепь событий, где участники попеременно выдают стимулы друг для друга.
Правила реагирования позволяют делать прогнозы значимости предполагаемого развития ситуации и переоценивать прежний опыт. Это продолжение развития функции сомнения в адекватности штатных автоматизмов, рассмотренное выше, но уже на более глубоком уровне прогнозирования, с учетом динамики развития ситуации, с заглядыванием на несколько шагов вперед, но пока только строго внутри одного правила. Имея хотя бы короткие цепочки кадров ЭП в 2-3 звена, можно перед выполнением автоматизма посмотреть свой прошлый опыт – вдруг на следующий стимул от Beast, согласно сохраненной истории подобного диалога, от Оператора последует негативная ответная реакция? Шахматисты всегда заглядывают на несколько ходов вперед. Если опыт предсказывает негатив, стоит тормознуть начало такого сценария развития и подумать об альтернативе. Может быть и обратная ситуация, когда эффект на первых шагах сохраненного диалога негативный, а в конце позитивный, причем настолько, что перекрывает весь первоначальный негатив. Тогда стоит выполнять автоматизм, несмотря на негативный эффект, записанный в правилах.
Рассмотрим это на примере создания Правил реагирования в проекте Beast:
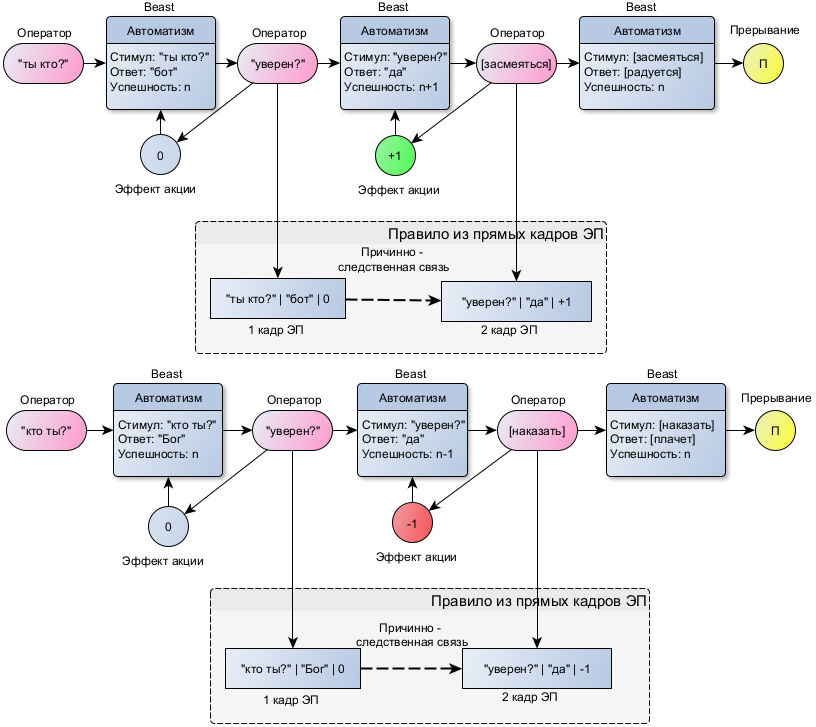
В результате двух проведенных диалогов, разделенных периодом пассивного ожидания или сменой тематического контекста, сформировалось два правила. В первом активация автоматизма «уверен?» - «да» была оценена положительно, во втором отрицательно. В итоге, хотя автоматизм и не был заблокирован, например, по причине его достаточно высокой успешности, при повторе диалогов Beast, видя негативный прогноз по второму правилу, остановит активацию на первом шаге диалога, выдав смятение, ступор: «кто ты?» - … Словно он «понимает», что, если он назовется Богом, его накажут. Хотя понимание в данном случае на самом примитивном уровне, но оно уже возникает и по мере привлечения более сложных механизмов становится все более осознаваемым (привлекающим к себе субъективное внимание).
На уровне рефлекторного реагирования говорить о самоощущении, и тем более понимания чего либо, не корректно потому, что для функционирования такой модели не требуется оценочный механизм успешности выполнения рефлекса для особи, он выполняется механически. Успешность «рефлекторного существа» определяется естественным отбором на уровне поколений. А где нет ощущений – нет и ничего вышестоящего, которое базируется на них. Поэтому рассуждать о природе таких психических феноменов как сознание, корректно только опираясь на наличие и степень развитости определенных механизмов, которые и обеспечивают этот феномен. Сознание становится как бы «размазанным» по стадиям развития существа, по его механизмам адаптации.
Рассмотрим на примере схемы Beast, как происходит постепенное усложнение осознаваемой адаптивности, при каких условиях активируется 1 и 2 уровни осознания ситуации.
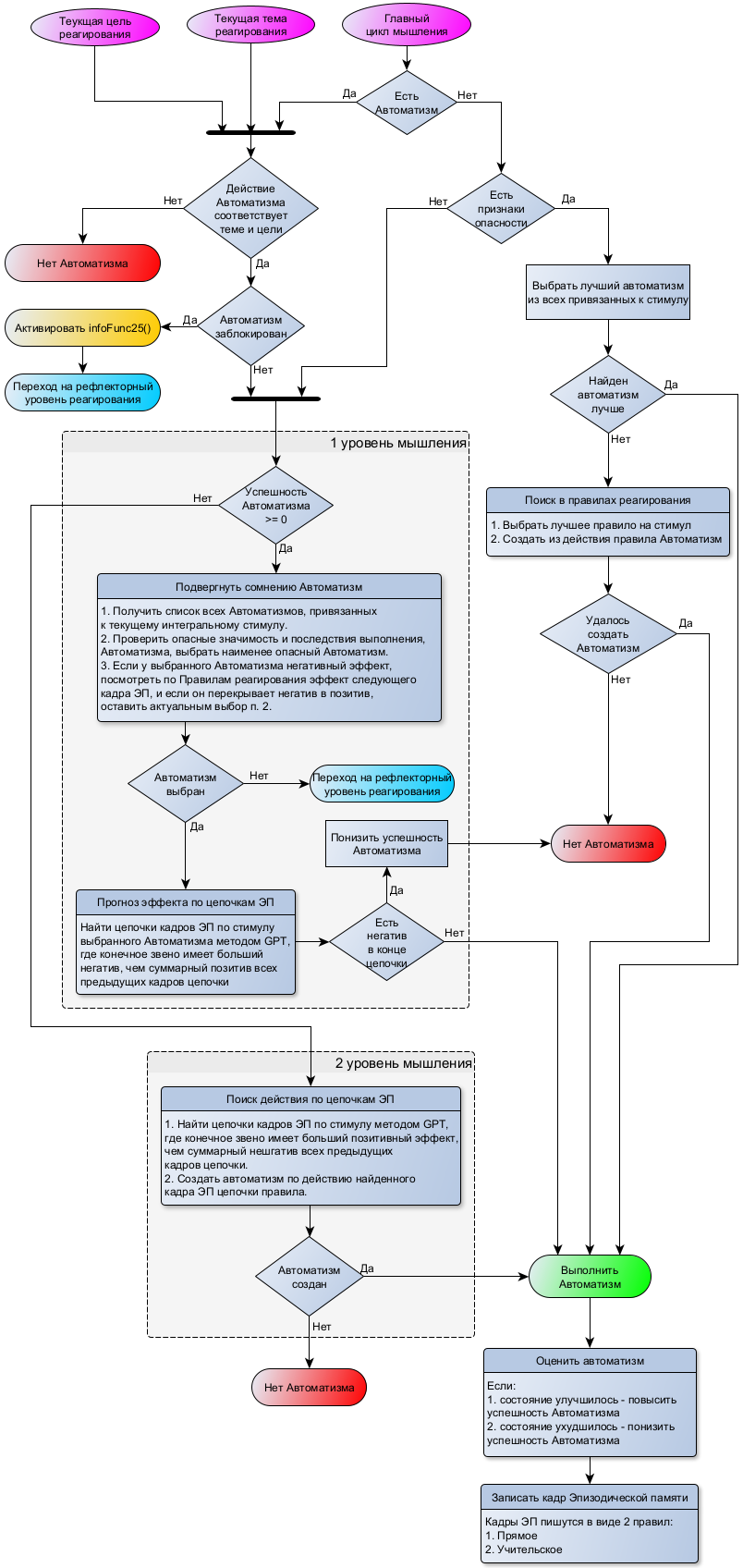
Если по стимулу нашелся штатный автоматизм с успешностью >=0 и нет признаков опасности ситуации, то активируется 1 уровень мышления, который на основании прошлого опыта определяет, насколько допустимо выполнить привычное действие (запустить штатный автоматизм). Если оказывается, что недопустимо, например, согласно опыту предполагается негативные последствия, не перекрываемые последующими позитивными, активируется второй, более глубокий уровень мышления и начинается опять же на основе прошлого опыта поиск нового варианта действия. Если ничего подходящего не нашлось, мышление переходит на следующий по иерархии, 3 уровень, который на схеме не показан, но выделены маркеры такого перехода. Это выход из схемы через элементы «Нет автоматизма».
Если совсем коротко обобщить суть этих первых двух уровней осмысления, то можно сказать так:
- Первый уровень отвечает на вопрос: приводит ли привычное действие к негативным последствиям в новых условиях? Если да, то делается попытка заменить его на альтернативное из имеющегося набора.
- Воторой уровень отвечает на вопрос: Какое действие согласно опыту правил можно совершить в данных условиях, если оно не совершено на первом уровне.
При этом становится очевидным порядок иерархии активации уровней: если привычное действие оказалось не приемлемым в текущих условиях, нужно искать новое. То есть сначала быстрая проверка на адекватность реакции в текущих условиях, и только потом более долгий поиск нового варианта реагирования. Оба они используют эпизодическую память, структурированную в виде правил, причем на 2 уровне поиск ассоциативный: не только по полному стимулу, но и по частичному. Например: заметив по ходу движения лужу, на первом уровне ясно, что просто привычно шагать по ней не следует, а на втором уровне подбирается подходящее правило для этой ситуации и мы можем «машинально», «не задумываясь» ее перешагнуть или перепрыгнуть или обойти. Но в случае если лужа глубокая, большая, активируется третий уровень, мы останавливаемся чтобы подумать (вот тут включается мышление) и начнется более глубокий поиск в прошлом опыте. 3 уровень, обычно и связывают с сознанием потому, что в нем намного ярче проявляется ощущение ситуации, словно внезапно открылись глаза. Хотя на самом деле они открывались постепенно, строго по иерархии усложнения проблемы: если задача не решается на текущем уровне, переходим на следующий, более сложный. Процесс «просыпания» осознанности как бы повторяет эволюционный путь ее формирования потому, что каждый новый механизм базируется на старом и не может запуститься без него. Как лампочки в гирлянде типа «бегущие огни», соединенные последовательно: каждая из них загорается, только если загорелась предыдущая.
По мере накопления Правил реагирования, естественным образом возникает необходимость делать их обобщения. Для любой базы данных, достигшей определенного объема, становится все более актуальной проблема ускорения (оптимизации) поиска разносторонней информации, которую уже не решить одним лишь повышением производительности оборудования. Необходима структуризация, оптимизирующая доступ к группам данных, собираемых по какому-то признаку. А при развитии таких механизмов открывается возможность делать прогнозы по произвольно выбранному, а не текущему стимулу. Это уже означает переход от пассивной адаптации, когда из прошлого опыта подбирается оптимальный вариант реагирования на стимул, к активной провокационной, когда реагирование подбирается так, чтобы получить ответный стимул с целевым, предположительно нужным эффектом. И вот здесь уже намного более явно проявляется понятие Цель реагирования (fornit.ru/67888).
На предыдущих уровнях развития цель возникала естественным образом как необходимость нормализации критически важных жизненных параметров. Под нее эволюционным отбором подбирались рефлексы, модифицировались автоматизмы потому, что это давало преимущество в адаптации: кто более успешно и быстро приводит свои жизненные параметры в норму, тот очевидно более жизнеспособен и плодовит. Но такая цель как бы «механическая», она заложена по умолчанию в самом определении жизни и не требует никаких маркеров успешности ее достижения кроме оценок стало лучше/стало хуже в отношении к состоянию жизненных параметров. В случае провокационного реагирования задача существенно усложняется: может оказаться, что провокационные стимулы сами по себе оказывают негативное влияние на гомеостаз. Терпеть боль ради достижения поставленной цели, преодолевать страх, действовать вопреки четким и ясным сигналам маркеров системы гомеостаза, однозначно показывающих, что данное действие вредоносно и не допустимо. Такое стратегическое планирование, в отличие от прежнего ситуативного, открывает существенно более высокие возможности в адаптации, не доступные на прежнем уровне. А все предпосылки для его появления уже подготовлены, поэтому был лишь вопрос времени, когда появится подходящая мутация и даст толчок эволюции, которая как снежный ком тут же начнет наращивать и развивать столь полезный функционал.
Новый тип цели является развитием предыдущей гомеостатической. Ведь так или иначе, все равно любая адаптация сводится к оптимальной балансировке уровней жизненных параметров. Другое дело, что задачу можно пытаться решить в лоб, одним действием, или стратегически, собрав цепочку последовательных действий ведущих к той же цели – вернуть в норму жизненные параметры. Но для этого придется делать шаги, иногда ведущие к их ухудшению: сделать шаг назад, чтобы, разбежавшись, прыгнуть на два шага вперед. Поэтому следующим эволюционным новшеством, без которого цепочки действий просто блокировались отрицательной гомеостатической значимостью, стал механизм ее подавления – волевое усилие, которое необходимо для преодоления негативных последствий выполняемого действия.
Все эти эволюционные наработки способствовали развитию такого психического феномена как «ощущение» потому, что для более долгих ассоциативных поисков, сопоставления значимостей выделенных объектов, глубокого прогнозирования, требовалось удержание образа цели, чтобы все эти действия выполнялись в общем контексте динамически меняющейся ситуации. Это привело в конечном итоге к развитию интегральной картины информации о ситуации, которая является для субъекта ощущением или переживанием значимости происходящего и прогнозами последствий этой значимости. Кроме того, так как незавершенных целей может накапливаться много, требуется актуализация одной из них потому, что не всегда возможно одновременно достигать разных целей, так как они могут быть взаимно антагонистичными. Это потребовало формирования механизма контрастирования текущих целей для выделения наиболее актуально-значимой для ее текущего осмысления. Все эти психические процессы, сами по себе кратковременные, но проходящие в общем контексте образа цели, формируют постоянно меняющуюся с каждой мыслью информационную картину восприятия, сопровождающую процесс решения проблемы достижения цели, которая и создает субъективный феномен «ощущения», «осознания». Когда мы что-то «чувствуем», «видим», «понимаем» и «задумываемся» – это результат работы инфо-функций, запросы к которым дают новую информацию для понимания ситуации, формируют модель, по которой впоследствии можно быстро, уже не «задумываясь» прогнозировать значимости различных действий, которые мы можем совершить с объектом. Например, если мы «видим» табуретку посреди комнаты, то мы уже «знаем»: она не подпрыгнет внезапно до потолка, не бросится на нас, на нее можно присесть и она не развалится, она твердая, и т. д. Все эти варианты развития ситуаций взаимодействия с ней мы «осознаем» как бы одним общим образом понимания – это табуретка. При этом в случае необходимости можно быстро получить прогноз, что будет со мной, если я… И стоит хоть чему то из ключевых признаков этого интегрального образа, включающего в себя не только статическую визуальную картину, но и динамическую модель «поведения табуретки» измениться, например она вдруг начнет двигаться или приподнявшись повиснет в воздухе – тут же сработает ориентировочный рефлекс по такой значимой новизне и внимание мгновенно актуализирует проблему: произошло расхождение между текущей моделью понимания и реальностью. Снова начнется работа инфо-функций, поиск подходящей модели, и пока он идет – мы ничего не «понимаем», хотя буквально только что все было ясно и очевидно. Если все привычные модели понимания станут не адекватными реальности, например мы окажемся в ситуации, для которой у нас нет никакого опыта реагирования, возникает ступор и ощущения начинают пропадать: теряется чувство времени и себя в пространстве, прекращается запись эпизодической памяти, мы потом ничего не помним – и все реагирование откатывается на древний, примитивный «бездумный» уровень потому, что действительно, думать в данной ситуации технически не возможно – нет базовой модели понимания.
Итак, если совсем коротко: ощущение, понимание чего либо, и в более обобщенном смысле осознание чего либо – это результат работы механизма обработки информации при удержании вниманием актуально-значимого образа. Удерживается актуальным вниманием всегда только один образ, поэтому понимать и ощущать мы одномоментно можем только что-то одно. Но в процессе постоянного переключения внимания между образами, которое происходит при каждом изменении (переактивации) инфо-картины восприятия возникает эффект множественного восприятия: мы видим в окне двор, там скамейка, на ней кто то сидит и т. д. Переактивация инфо-картины может быть объективной, если была спровоцирована реальными изменениями, или субъективной, если какая то инфо-функция запустила прогноз по правилам и возникла «воображаемая» модель понимани. Вот демо-анимация процесса осознания.
В модели Beast для реализации процесса мышления используется дерево понимания нерешенных проблем, в котором иерархически представлены уровни понимания возникшей проблемы данной ситуации. Дерево понимания задает границы применения привычного автоматизма, в первую очередь целевые, что определяет многовариантный смысл автоматизма и позволяет решить проблему с их многозначностью, возникающей уже на третьей стадии: какой автоматизм, для каких ситуаций, в каких темах и для каких целей можно использовать в плане адаптации. По сути, такая привязка определяет набор действий, необходимых для достижения цели. С другой стороны, можно сказать, что это дерево определяет дополнительные пусковые стимулы, которые не могут быть изначально жестко заданы в дереве автоматизмов, и поэтому вынесены в отдельную группу. Динамика активации этого дополнительного дерева пусковых стимулов определяется произвольностью выбора темы и цели, которая формируется в конкуренции тем по весу значимости, выделяя наиболее важную тему в текущей ситуации для осмысления, и в конкуренции целей по значимости их достижения. Рассмотрим формирование дерева понимания Beast на общей схеме:
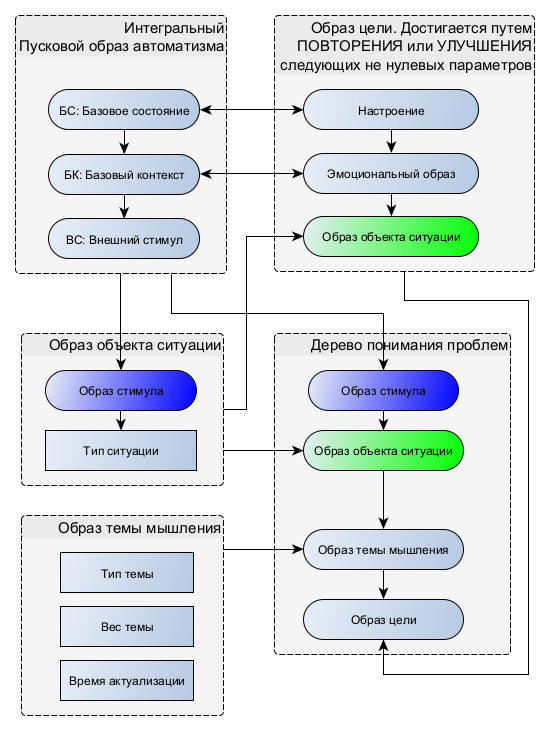
Образ Объекта ситуации и Образ темы мышления – это результат обобщения личного опыта (кадров ЭП), о котором говорилось выше. Они позволяют выделять группу стимулов (Объект ситуации) и группу ментальных действий (Тема мышления), чтобы удерживать процесс мышления в одном общем контексте. Составляющие Образа цели Настроение и Эмоция могут перекрывать гомеостатические Базовое состояние и Базовый контекст соответственно, что позволяет активировать автоматизм, не относящийся к текущей гомеостатической цели реагирования. Так становится возможным действовать вопреки гомеостатической значимости, если произвольно изменены Настроение и Эмоция.
В примитивном случае Образ цели определяет 2 критерия ее достижения:
- улучшить текущие эмоции, что приведет к улучшению настроения
- повторно активировать текущие эмоции, что приведет к поддержанию уже хорошего настроения
Смысл таких действий в том, чтобы найти и активировать те автоматизмы, что приводят к улучшению настроения, что в свою очередь предполагает их субъективную оценку как «правильные». То есть если на уровне гомеостатической регуляции адаптивности «правильность» корректирующих действий определялась нормализацией Жизненных параметров, которая происходила после их выполнения, то на уровне психической регуляции адаптивности правильность становится более абстрагированной от гомеостаза и определяется субъективной оценкой – субъективным приданием значимости, которая может и не совпадать с гомеостатической. Но так как настроение и эмоция это первые два уровня дерева автоматизмов, то изменяя их можно произвольно активировать автоматизмы. Этим определяется произвольность выбора, как способность выполнять действие, альтернативное привычному («автоматичному»). При этом без произвольного вмешательства, «по умолчанию», эмоциональное состояние на уровне психики является абстракцией состояния гомеостатической ситуации.
Формирование системы гомеостаза в процессе филогенеза От безусловных рефлексов к условным От рефлексов к автоматизмам От бездумного к осознанному