Системная нейрофизиология (nan)
Двухканальный подход к орфографической обработке
Редактироватьс одной стороны, оптимизация включает в себя выбор сочетаний букв, которые являются наиболее информативными с точки зрения идентификации слова (ограничение диагностичности), а с другой стороны, включает в себя обнаружение сочетаний букв, которые соответствуют ранее существовавшим сублексическим фонологическим и морфологическим представлениям (ограничение на разбиение на фрагменты).
Точная схема кодирования букв по центру слова позволяет разделять часто встречающиеся сочетания букв, такие как многобуквенные графемы и аффиксы, независимо от места фиксации взгляда в слове. Разработка параллельной версии этого детализированного орфографического кодирования особенно важна для извлечения суффиксов или рифм, для которых положение составляющих букв определяется относительно окончаний слов.
Для печатных слов мы предполагаем, что это включает в себя выбор буквосочетаний, которые максимально повышают видимость составляющих их букв и максимально увеличивают объем информации, которую они несут в отношении идентичности слова.
Вес уверенности:
В настоящем теоретическом обзоре мы исследуем, как различные ограничения в обучении, которые, как считается, влияют на оптимизацию соответствия печатного текста смыслу при чтении, могут влиять на характер орфографического кода, используемого при квалифицированном чтении. Предполагается, что, с одной стороны, оптимизация включает в себя выбор сочетаний букв, которые являются наиболее информативными с точки зрения идентификации слова (ограничение диагностичности), а с другой стороны, включает в себя обнаружение сочетаний букв, которые соответствуют ранее существовавшим сублексическим фонологическим и морфологическим представлениям (ограничение на разбиение на фрагменты). Эти два ограничения приводят к появлению двух различных типов дословного орфографического кода, крупнозернистого и мелкозернистого кода, связанного с двумя маршрутами двухмаршрутной архитектуры. Обработка по крупнозернистому маршруту оптимизирует быстрый доступ к семантике за счет использования минимальных наборов букв, которые максимизируют информацию об идентичности слова, при кодировании для приблизительного расположения букв внутри слова независимо от их смежности. С другой стороны, обработка по мелкозернистому маршруту чувствительна к точному порядку букв, а также к расположению относительно начала и окончания слов. Это позволяет объединять часто встречающиеся сочетания букв, которые образуют соответствующие единицы для морфо-орфографической обработки (префиксы и суффиксы) и для сублингвального перевода печатного текста в звуковой (многобуквенные графемы).
Вступление
Отправной точкой настоящей работы является традиционная модель чтения вслух с двумя способами, в которой проводится различие между лексическим и не лексическим способами преобразования текста в звук (Ellis and Young, 1988; Coltheart et al., 1993, 2001; Zorzi, 2010). Лексический путь часто называют прямым путем, при котором сублексическая орфографическая информация вступает в прямой контакт с орфографическими представлениями целых слов, которые затем обеспечивают доступ к фонологии целых слов, с одной стороны, и семантической информации более высокого уровня - с другой. По так называемому косвенному, не лексическому пути, сублексическая орфографическая информация сначала преобразуется в сублексический фонологический код, а затем вступает в контакт с фонологическими выходными единицами, фонологическими представлениями целых слов и семантикой. В своей новейшей форме двухсторонний подход обеспечивает всестороннее описание явлений, связанных с процессом чтения вслух у взрослых, умеющих читать, и у людей с дислексией (Perry et al., 2007, 2010).
Этот общий подход был принят для беззвучного чтения слов в двухмодальной модели интерактивной активации (BIAM, см. рисунок 1; Грейнджер и Ферранд, 1994; Джейкобс и др., 1998; Грейнджер и Зиглер, 2008; Дипендаэле и др., 2010). BIAM можно рассматривать как локальную реализацию общего разделения труда или “треугольного” подхода к визуальному распознаванию слов, при котором существует два пути от орфографии к семантике – прямой путь и косвенный путь через фонологию (Зайденберг и Макклелланд, 1989; Плаут и др., 1996). Специфическая архитектура BIAM позволяет ей учитывать широкий спектр явлений, связанных с визуальным распознаванием слов, и, в частности, быстрое вовлечение фонологических кодов в процесс беззвучного чтения слов (Braun et al., 2009; Diependaele et al., 2010; см. Грейнджер и Зиглер, 2008, для ознакомления).
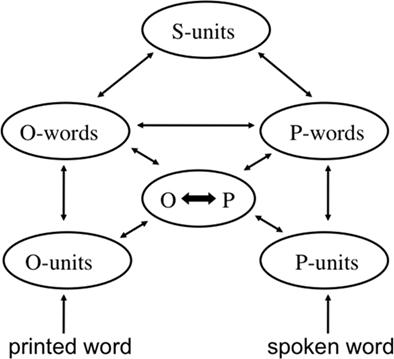
Рисунок 1. Общая архитектура бимодальной модели интерактивной активации (BIAM). Проводится различие между сублексическими и лексическими орфографическими (O-единицы, O-слова) и фонологическими (P-единицы, P-слова) представлениями, которые взаимодействуют через центральный интерфейс (O ↔ P). Представления в виде целых слов обеспечивают доступ к семантическим представлениям (S-единицам).
Большая часть успеха этого общего подхода заключается в применении принципа вложенного инкрементального моделирования (Джейкобс и Грейнджер, 1994; Грейнджер и Джейкобс, 1996; Перри и др., 2007). Этот принцип поощряет разработку моделей, основанных на предыдущих успехах и адаптирующихся к предыдущим неудачам. В этом отношении BIAM включает в себя ключевые аспекты модели интерактивной активации Макклелланда и Румельхарта (1981), а также расширение этой модели Грейнджером и Джейкобсом (1996), которая была предложена для учета определенного количества специфических для конкретной задачи явлений, связанных с визуальным распознаванием слов. Кроме того, важно отметить, что два относительно независимых направления исследований, одно из которых сосредоточено на изучении смысла чтения про себя (как в настоящей работе), а другое - на чтении вслух (Perry et al., 2007, 2010), пришли к очень похожим предложениям относительно общей архитектуры распознавания слов и читал вслух. Именно эта общая архитектура лежит в основе настоящей теоретической работы.
Одной из ключевых особенностей многих моделей визуального распознавания слов, включая BIAM, является то, что существует единый тип сублексического орфографического кода. Некоторая форма кода расположения букв по центру слова, такая как щелевое кодирование, используемое в модели интерактивной активации (McClelland and Rumelhart, 1981), обычно применяется для того, чтобы связать разные идентификаторы букв с разными позициями в слове. В двухканальных моделях чтения этот уникальный сублексический орфографический код активирует как орфографические представления целого слова (прямой путь), так и сублексические фонологические представления (косвенный путь).
В настоящей статье мы описываем двухсторонний подход к орфографической обработке, который постулирует существование двух принципиально разных типов орфографических кодов, не зависящих от местоположения, ориентированных на слова, сублексических орфографических кодов. Предполагается, что эти два типа орфографических кодов возникли в результате природы ограничений, которые влияют на формирование орфографических представлений при чтении (Грейнджер и Дюфау, 2011). Основанием для проведения такого различия послужило рассмотрение уровня точности кодирования положения букв, который необходим для успешного сублексического преобразования печатного текста в звуковой, с одной стороны, и растущего количества доказательств существования гибкого, относительно неточного сублексического орфографического кода, с другой. Последняя форма доказательств стимулировала разработку ряда схем кодирования положения букв в качестве альтернативы схеме Макклелланда и Румельхарта (1981), основанной на слотах, и схеме викельграфа Зайденберга и Макклелланда (1989) (например, Whitney, 2001; Грейнджер и ван Хойвен, 2003; Гомес и др., 2008; Дэвис, 2010). Все альтернативные схемы, включая предложенную Грейнджером и ван Хойвеном (2003), которая будет описана ниже, предусматривали повышенную гибкость в привязке идентификаторов букв к положению внутри слова.
В следующих разделах мы сначала опишем двухсторонний подход к орфографической обработке и то, как он возник из рассмотрения ограничений, возникающих при обучении сопоставлению орфографии с семантикой, с одной стороны, и орфографии с уже существующими сублексическими морфологическими и фонологическими представлениями, с другой стороны. Затем мы опишем, как этот подход может быть интегрирован в общую архитектуру BIAM, и обсудим его последствия с точки зрения фонологических и морфологических влияний при визуальном распознавании слов. Наконец, мы обсудим значение этого общего подхода для описания процесса овладения чтением, а также возможную роль внимания в различении между изучением мелкозернистых и крупнозернистых орфографических представлений, что составляет основу нашего двухстороннего подхода.
Сложная проблема орфографической обработки
Отправной точкой подавляющего большинства вычислительных моделей орфографической обработки является орфографический код, ориентированный на слова. Таким образом, эти модели позволяют избежать сложной проблемы орфографической обработки, то есть преобразования ретинотопической визуальной информации, зависящей от местоположения, в орфографический код, ориентированный на слова, не зависящий от местоположения. Во время чтения глаза фиксируют большинство слов в тексте, в основном только один раз, и восприятие информации из зафиксированного слова зависит от положения фиксации в слове. Таким образом, мозг читателя изначально знает, что визуальная информация, связанная с идентичностью данной буквы, находится в определенном месте относительно фиксации взгляда (т.е. в ретинотопических координатах). Однако для идентификации уникального орфографического слова требуется знание того, где находится данная буква в слове, а не на сетчатке глаза.
Грейнджер и ван Хойвен (2003) предложили решение, вдохновленное основополагающей работой Мозера (1987) и последующим развитием этого подхода Уитни (2001). В модели орфографической обработки Грейнджера и ван Хойвена (рис. 2) алфавитный массив кодирует наличие данной буквы в данном месте относительно фиксации глаза вдоль горизонтального меридиана. В нем не указано, где находится данная буква по отношению к другим буквам в стимуле, поскольку каждая буква обрабатывается независимо от всех остальных. Таким образом, обработка на уровне алфавитного массива нечувствительна к орфографической регулярности буквенных строк. Однако для целей распознавания слов, не зависящих от местоположения, эта карта, привязанная к конкретному местоположению, должна быть преобразована в код, ориентированный на слова, таким образом, чтобы идентификация букв была привязана к положению внутри слова (где слово определяется как последовательность букв, разделенных пробелами) независимо от местоположения на сетчатке (см. Карамацца и Хиллис, 1990). Чтобы выполнить это преобразование, Грейнджер и ван Хойвен (2003), вслед за Мозером (1987) и Уитни (2001), предложили механизм, который они назвали кодированием с использованием “открытой биграммы”. В схеме Грейнджера и ван Хойвена открытые биграммы кодируют наличие упорядоченных пар букв независимо от их смежности. Следовательно, точно такое же представление в виде открытой биграммы (например, T-A) было бы активировано словами, содержащими эти две буквы в указанном порядке, независимо от количества промежуточных букв (например, таблица, поезд, трэш)1. Другими словами, этот тип представления “знает”, что данная пара букв присутствует в стимуле в определенном порядке, но не “знает”, находятся ли эти две буквы рядом друг с другом или нет.
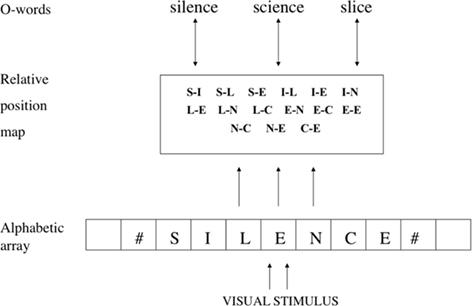
Рисунок 2. Модель орфографической обработки, разработанная Грейнджером и ван Хойвеном (2003). Детекторы букв, зависящие от местоположения (алфавитный массив), отправляют информацию в сублексические орфографические представления, ориентированные на слова (карта относительного расположения), которые, в свою очередь, активируют орфографические представления целых слов (О-слова).
Однако, как указывают Госвами и Зиглер (2006), такого рода гибкий орфографический код вряд ли может обеспечить надлежащие исходные данные для сублексического перевода орфографии в фонологию. Чтобы вычислить идентичность сложных графем, таких как “sh”, вам нужно знать, что H следует непосредственно за S. Знание того, что S находится где-то перед H (как в схеме кодирования с использованием открытой биграммы), привело бы к возникновению слишком большого количества ложноположительных ошибок кодирования или ошибок привязки (фон дер Мальсбург, 1999), таких как определение наличия сложной графемы “sh” в слове “сахара”. Это наблюдение позволяет предположить, что начальная фаза орфографической обработки в модели Грейнджера и ван Хойвена (2003), а именно алфавитный массив, должна использоваться в двух различных типах сублексических кодов, не зависящих от местоположения. Это основа нашего двухканального подхода к орфографической обработке, который будет более подробно описан ниже. Однако, в отличие от альтернативных двухпутевых подходов к орфографической обработке (например, Уитни и Корнелиссен, 2005, 2008), мотивация, стоящая за двумя путями в нашем подходе, не основана на традиционном различии между прямыми “орфографическими” и косвенными “фонологическими” путями при чтении, хотя, как мы показываем, существует четкая связь с этой традицией. Как указывалось выше, основная мотивация, лежащая в основе двух типов орфографического кода в нашем двухстороннем подходе, возникает из рассмотрения различных типов ограничений, которые действуют в процессе обучения чтению, и разработки сублексических орфографических представлений, не зависящих от местоположения.2 Предполагается, что эти ограничения подталкивают систему к разработке диагностических признаков (буквосочетаний) для идентификации слова, с одной стороны, и кластеров часто встречающихся букв, имеющих функциональное значение, с другой. Эти аргументы рассматриваются более подробно в следующем разделе.
Двухсторонний подход к орфографической обработке для опытных читателей
Поскольку основное внимание уделяется беззвучному чтению слов, общая цель наших усилий по моделированию состоит в том, чтобы учесть, как, учитывая ограничения на видимость букв в строке, а также временные ограничения, накладываемые скоростью чтения (около 250 мс на слово), опытный читатель оптимизирует восприятие информации из стимула печатного слова для того, чтобы восстановить соответствующую семантическую информацию, необходимую для понимания текста. Двухмаршрутный подход учитывает, что на обработку по двум маршрутам влияют два различных типа ограничений. Оба типа ограничений определяются частотой, с которой в печатных словах встречаются различные сочетания букв. С одной стороны, частота встречаемости определяет вероятность того, что данное сочетание букв относится к читаемому слову. Буквосочетания, которые реже встречаются в других словах, в большей степени определяют идентичность обрабатываемого слова. В крайнем случае, сочетание букв, которое встречается только в одном слове языка и поэтому является редким явлением при рассмотрении языка в целом, является весьма информативным в отношении идентичности слова. С другой стороны, частота совпадений позволяет формировать представления более высокого порядка (группирование), чтобы уменьшить объем обрабатываемой информации за счет сжатия данных. Сочетания букв, которые часто встречаются вместе, могут быть сгруппированы для формирования орфографических представлений более высокого уровня, таких как многобуквенные графемы (th, ch) и морфемы (ing, er), что обеспечивает связь с ранее существовавшими фонологическими и морфологическими представлениями при чтении. Этот двухканальный подход к орфографической обработке проиллюстрирован на рисунке 3.
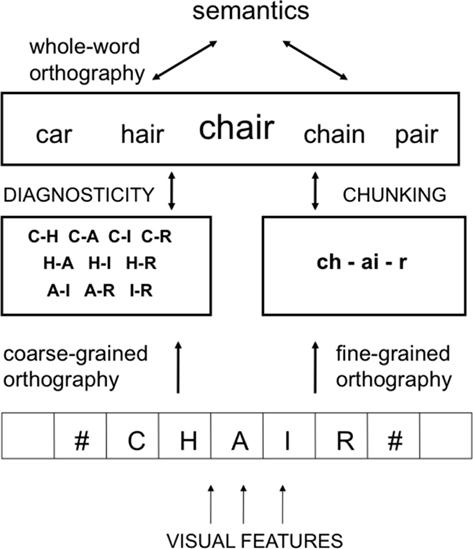
Рисунок 3. Двухканальный подход к орфографической обработке. Банк детекторов букв, зависящих от местоположения, отправляет активацию на два типа сублексических орфографических представлений, не зависящих от местоположения: (1) крупнозернистые представления, которые кодируют наличие информативных буквенных комбинаций в отсутствие точной информации о местоположении, и (2) мелкозернистые представления, которые кодируют наличие информативных буквенных комбинаций. часто встречающиеся буквосочетания (многобуквенные графемы, аффиксы). Крупнозернистый код оптимизирует соответствие орфографии семантике, выбирая сочетания букв, которые являются наиболее информативными с точки зрения идентификации слова (диагностичности), независимо от смежности букв. Детализированный код оптимизирует обработку за счет разбиения на фрагменты часто встречающихся смежных буквенных сочетаний.
Принципиально разные типы орфографической обработки выполняются двумя способами в рамках нашего двухканального подхода, поскольку они ориентированы на использование частоты встречаемости диаметрально противоположных способов. Эти два способа заметно отличаются друг от друга уровнем точности, с которой кодируется информация о положении букв. В одном случае вычисляется грубый орфографический код, позволяющий быстро определить уникальный идентификатор слова и соответствующие семантические представления (быстрый путь к семантике). Учитывая различия в видимости букв в строке, ключевая гипотеза здесь заключается в том, что лучший способ оптимизировать производительность - адаптировать обработку к ограничениям, налагаемым различиями в видимости букв и различиями в объеме информации, передаваемой различными сочетаниями букв. То есть стратегия этого маршрута заключается в кодировании комбинаций наиболее заметных букв, которые наилучшим образом определяют идентичность слова.
Кодирование для смежных и несмежных буквосочетаний в модели орфографической обработки, разработанной Грейнджером и ван Хойвеном (2003) (так называемое кодирование “открытой биграммой”: Уитни, 2001; Грейнджер и ван Хойвен, 2003; Грейнджер и Уитни, 2004; Дехейн и др., 2005), обеспечивает один из средства реализации этой конкретной стратегии. Ключевая идея, лежащая в основе этого предложения, заключается в том, что, учитывая различия в видимости букв в строке (например, Стивенс и Грейнджер, 2003), наиболее эффективным способом быстрого определения идентичности слова является вычисление порядка и идентификационной информации для наиболее заметных букв. Это предназначено не для того, чтобы быть надежным средством определения того, какое слово присутствует в тексте, а для обеспечения быстрой восходящей активации представлений целого слова, которые могут быть объединены с контекстуальными ограничениями, чтобы ориентироваться в правильном значении слова во время понимания прочитанного. В отсутствие таких дополнительных нисходящих ограничений обработка по более медленному мелкозернистому маршруту также при необходимости предоставит информацию, устраняющую неоднозначность3.
Эмпирические доказательства в пользу такого типа грубого орфографического кодирования были получены с использованием парадигмы маскированного прайминга в виде надежных эффектов прайминга с простыми числами с переставленными буквами (например, Гадрен-ГАРДЕН: Переа и Люпкер, 2004; Шунберт и Грейнджер, 2004), а также простых чисел подмножества и надмножества (например, grdn- ГАРДЕН, гамрдсен-ГАРДЕН: Перессотти и Грейнджер, 1999; Грейнджер и др., 2006а; Ван Аше и Грейнджер, 2006; Вельверт и др., 2008; обзор см. в статье Грейнджер, 2008). Открытое биграмное кодирование не только дает естественное объяснение этим эмпирическим демонстрациям гибкой орфографической обработки, но и в сочетании с ограничениями, связанными с видимостью букв и информативностью, может также объяснить более тонкие вариации в эффектах орфографической настройки в зависимости от положения орфографического перекрытия и конкретных используемых букв (например, согласные против гласных). Тем не менее, мы обращаем ваше внимание на то, что открытое биграммное кодирование является лишь одной из возможных реализаций метода крупнозернистой орфографической обработки в рамках нашего двухмаршрутного подхода. Замена этого механизма альтернативной схемой кодирования (например, Gomez et al., 2008) не нанесла бы ущерба нашему подходу, если бы новый механизм обладал ключевыми свойствами гибкости и максимально увеличивал использование диагностической информации с учетом ограничений на видимость букв.
В правой части рисунка 3 детализированный орфографический код предоставляет более точную информацию о порядке следования букв в строке. Этот детализированный код позволяет кодировать многобуквенные графемы и точно упорядочивать их в строке. Эти графемы затем активируют соответствующие фонемы, которые, в свою очередь, приводят к активации соответствующего фонологического представления целого слова и соответствующих семантических представлений (см. Perry et al., 2007, о конкретной реализации графемного синтаксического анализатора). Однако в настоящем теоретическом подходе мелкозернистый маршрут орфографической обработки не ограничивается случаем обработки графемных представлений. Здесь мы предполагаем, что этот путь в целом предназначен для точного определения позиций буквенных обозначений внутри строки, чтобы облегчить разбиение на фрагменты часто встречающихся сочетаний4 букв, таких как сложные графемы (например, TH, CH, OO) и небольшие морфемы (например, аффиксы, такие как RE, ED, ER, ING). Это позволяет орфографической информации вступать в контакт с ранее существовавшими сублексическими фонологическими и морфологическими представлениями. Более того, в соответствии с гипотезой о том, что фонемы являются хорошим кандидатом для таких сублексических фонологических представлений, для установления контакта с многочисленными фонемами, которые записываются одной буквой, требуются однобуквенные представления. Итак, как может быть закодирована информация о расположении букв в процессе детальной орфографической обработки?
Одним из решений могло бы стать использование щелевого кодирования с начальной и конечной точками привязки, как это было предложено Джейкобсом и др. (1998), вариант которого был принят в недавней работе по кодированию положения букв в письменной речи (Fischer-Baum и др., 2010). Фишер-Баум и др. (2010) предполагают, что положение буквы кодируется как от начала к концу, так и от конца к началу строки (схема, называемая кодированием положения буквы “с обоих концов”). В этом предложении применяются те же опорные точки, что и в работе Джейкобса и др. (1998), но расширяет кодировку в обоих направлениях, чтобы охватить все буквы, так что каждая буква в строке представлена дважды – с ее расположением относительно начала слова, с одной стороны, и ее положением относительно конца слова - с другой. Фишер-Баум и др. (2010) показали, что этот тип схемы кодирования обеспечивает более полное представление о типах орфографических ошибок у двух лиц, страдающих дисграфией, по сравнению с альтернативными схемами кодирования положения букв. Еще раз подчеркнем, что это одна из возможных реализаций детального орфографического кодирования в нашем двухканальном подходе. Замена этого конкретного механизма альтернативным механизмом не нанесла бы ущерба нашему подходу, если бы новый механизм обладал ключевым свойством точного кодирования позиции внутри слова, которое, как предполагается, облегчает разбиение на фрагменты часто встречающихся смежных буквенных сочетаний.
Почему человеческий мозг, подвергающийся воздействию печати, использует такой двухсторонний подход к обработке орфографических данных? Как предположили Грейнджер и Холкомб (Grainger and Holcomb, 2009), возможно, что эта двухуровневая архитектура возникает из-за того, что визуальное распознавание слов представляет собой смесь двух миров: одного, основным измерением которого является пространство – мир визуальных объектов; и другого, основным измерением которого является время – мир устной речи. язык. Таким образом, опытные читатели могли бы научиться извлекать выгоду из этой особенности, используя структуру в пространстве для оптимизации отображения орфографической формы на семантику и используя структуру во времени для оптимизации отображения орфографической формы на фонологию. Однако даже в области разговорного языка можно провести различие между диагностичностью и фрагментарностью. Таким образом, более общим ответом на поставленный выше вопрос было бы то, что оптимизация процессов идентификации (для любого типа объектов) включает в себя извлечение диагностической информации, с одной стороны, и упрощение обработки за счет сжатия данных - с другой.5 Из этого различия естественным образом вытекает двухсторонний подход в той мере, в какой для изучения этих двух типов кода, вероятно, будут задействованы принципиально разные механизмы. Важным следствием этого различия для моделей визуального распознавания слов является то, что мы должны искать не один тип сублексического орфографического кода, а различные типы орфографических кодов, которые разработаны для выполнения совершенно разных функций.
Орфография и фонология
Наш двухсторонний подход к орфографической обработке может быть легко интегрирован в более общие рамки BIAM визуального распознавания слов. На рисунке 4 описана многоуровневая модель распознавания печатных слов, которая, по сути, является расширением BIAM и включает в себя различие, проведенное между двумя типами сублексического орфографического кода. Как и BIAM, наша многоуровневая модель распознавания слов имеет много общего с двухуровневыми моделями чтения вслух (Coltheart et al., 2001) и, в частности, с моделью CDP (Perry et al., 2007, 2010). Модель, предложенная на рисунке 4, дает более четкое описание процесса обработки, связанного с переходом от печатного текста к смысловому с помощью одних только орфографических представлений, и проводит ключевое различие между орфографическими кодами, зависящими от местоположения, и орфографическими кодами, не зависящими от местоположения (ориентированными на слова).
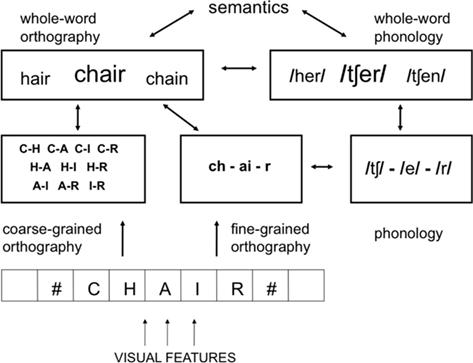
Рисунок 4. Многоуровневая модель понимания слов при беззвучном чтении, которая объединяет принцип двух типов сублексического орфографического кода, не зависящего от местоположения, в рамках общей бимодальной модели интерактивной активации (BIAM). Детализированный орфографический код обеспечивает уровень точности позиционного кодирования, необходимый для взаимодействия с сублексическими фонологическими представлениями. Обратите внимание, что различие между “прямыми” орфографическими и косвенными “фонологическими” путями в традиционных моделях с двумя маршрутами расширяется здесь за счет различия между двумя орфографическими путями.
Согласно модели, изображенной на рисунке 4, путь от печатного текста к смыслу через сублексические фонологические представления включает в себя тщательную орфографическую обработку. То есть система должна точно знать порядок следования различных букв в слове-стимуле (Госвами и Зиглер, 2006). Это особенно важно для извлечения смежных буквосочетаний, которые образуют многобуквенные графемные представления, такие как “ch” и “ai” в слове “стул”. Считается также, что это механизм, ответственный за извлечение других типов часто повторяющихся сочетаний смежных букв, таких как аффиксы.
Псевдогомофонные эффекты представляют собой один из ключевых эмпирических признаков тонкой орфографической обработки, поскольку общепризнано, что обработка таких стимулов включает в себя некоторую форму сублексического преобразования печатного текста в звуковой. Псевдомофоны - это не слова, которые могут произноситься как настоящие слова, например, буква “брана” произносится как слово “мозг”. Эти стимулы труднее отвергнуть как не относящиеся к словам в задаче на лексическое решение (например, Госвами и др., 2001; Циглер и др., 2001), генерируют больше ошибок семантической категоризации (например, Ван Орден, 1987) и являются более эффективными простыми числами по сравнению с тщательно подобранными орфографическими контрольными (например, Перфетти и Белл, 1991; Ферран и Грейнджер, 1994; Лукатела и Турви, 1994; Циглер и др., 2000; Frost et al., 2003; Grainger et al., 2003; обзор см. в Rastle и Brysbaert, 2006).
Наша многоуровневая модель дает одно ключевое предсказание относительно эффектов псевдомофонных простых чисел. Эти эффекты должны быть устранены с помощью манипуляций с транспонированными буквами, поскольку для детальной обработки, которая генерирует сублексический фонологический код, требуется точная информация о порядке букв. То есть, согласно нашему подходу, для создания эффекта псевдомофонной инициализации требуется точная информация о порядке букв, поскольку представления фонем активируются с помощью мелкозернистого орфографического кода. Итак, одно ключевое эмпирическое явление послужило основной мотивацией для теоретического перехода от чрезмерно точных схем кодирования положения букв, таких как схема щелевого кодирования в модели интерактивной активации (McClelland and Rumelhart, 1981), к более гибким схемам кодирования, таким как кодирование с использованием открытых биграмм. Это было следствием перестановок букв, наблюдавшихся в экспериментах с замаскированным праймингом (например, Переа и Люпкер, 2004; Шунберт и Грейнджер, 2004), или задержек при выборе слов, не связанных с выбором слов, или ошибок при выборе лексики без предварительной подготовки (например, Чемберс, 1979; О'Коннор и Форстер, 1981; Эндрюс, 1996; Переа и др., 2005). Жесткие схемы щелевого кодирования не могут учитывать эффекты перестановки букв (обзор см. в Grainger, 2008). Следовательно, учитывая гипотезу о том, что только мелкозернистое орфографическое кодирование, а не грубозернистое кодирование, может генерировать точное сублексическое фонологическое представление последовательности букв, и в предположении, что эффекты псевдомофонного прайминга дополняются сублексической фонологией (см. обзор Rastle and Brysbaert, 2006), затем мы предсказываем, что введение перестановки букв в псевдомофонный стимул должно лишить его способности создавать соответствующее базовое слово. Ача и Переа (2010) сравнили эффекты прайминга для слов, состоящих из переставленных букв (например, канисо–КАЗИНО против кавиро–КАЗИНО) и псевдомофоны из переставленных букв (например, канисо–КАЗИНО против кавиро–КАЗИНО). Они обнаружили стандартный эффект прайминга TL для простых слов TL, но не обнаружили эффекта прайминга для псевдомофонных простых чисел TL, как и предсказывал наш двухпутевой подход.
Еще одно доказательство в пользу этого двойного подхода получено в результате экспериментов, которые манипулируют орфографической правильностью и произносимостью несловесных стимулов, создаваемых перестановкой букв (Frankish and Turner, 2007; Frankish and Barnes, 2008). Перестановка двух букв базового слова “storm”, например, может привести либо к ортостатически и фонотактически правильному неслову, такому как “strom”, либо к ортостатически и фонотактически неправильному неслову, такому как “sotrm”. Фрэнкиш и его коллеги обнаружили, что недопустимые не-слова легче воспринимались как соответствующие базовые слова в задаче перцептивной идентификации, а для того, чтобы отклонить их как не-слова в задаче лексического решения, требовалось больше времени (Фрэнкиш и Тернер, 2007)., и были более эффективными простыми числами для соответствующих базовых слов-мишеней в эксперименте с маскированным праймированием (Frankish and Barnes, 2008). Мы согласны с Франкишем и Тернером (Frankish and Turner, 2007) и Франкишем и Барнсом (Frankish and Barnes, 2008) в том, что снижение эффекта TL, наблюдаемое при использовании легальных несловес, скорее всего, отражает более эффективное вычисление фонологического кода с использованием такого рода несловес по сравнению с нелегальными несловесами. Этот фонологический код, сгенерированный с помощью мелкозернистого метода обработки в нашей модели, повлиял бы на результаты крупнозернистого метода обработки, что уменьшило бы доказательства в пользу наличия базового слова (доказательства, полученные с помощью крупнозернистого метода обработки).
Более того, в соответствии с архитектурой BIAM и ее расширением в виде модели с несколькими маршрутами, показанной на рисунке 4, мы знаем, что фонологические факторы, влияющие на визуальное распознавание слов, действуют быстро (Braun et al., 2009), но, тем не менее, требуют больше обработки, чем требуется для получения чисто орфографических данных. эффекты. Этот различный временной ход эффектов был неоднократно выявлен в исследованиях замаскированного орфографического и фонологического прайминга (Ферран и Грейнджер, 1994; Зиглер и др., 2000). Это также было выявлено в ходе исследований, сочетающих маскированный прайминг и регистрацию потенциалов, связанных с событиями (ERPs: Grainger et al., 2006b). Наиболее важным является то, что в последнем исследовании сравнивалось использование простых чисел с переставленными буквами (например, barin-BRAIN против bolin–BRAIN) с использованием псевдомофонных простых чисел (например, brane–BRAIN против brans-BRAIN). Эффекты транспонированных простых букв были замечены в сигналах ERP примерно за 50 мс до появления эффектов псевдомофонной инициализации.
Наконец, в будущей работе необходимо будет точно изучить, как сублексическое орфографическое разбиение на фрагменты, которое, как предполагается, должно работать в рамках мелкозернистой орфографической обработки, может сочетаться с графемическим анализатором для преобразования графем в фонемы, например, реализованным в CDP (Perry et al., 2007) и BIAM (Diependaele и др., 2010). Одна из возможностей в рамках схемы кодирования “с обоих концов” для детальной орфографической обработки, описанной выше, заключается в добавлении последовательного графемического анализатора от начала до конца, который работает с буквенными представлениями, закодированными относительно начала слова. Этот синтаксический анализатор с фонологическими ограничениями будет взаимодействовать с орфографически управляемым механизмом фрагментации, усиливая представления, которые являются как орфографически, так и фонологически ограниченными, например, часто встречающиеся сложные графемы. Здесь мы подразумеваем, что чисто орфографические ограничения должны быть дополнены фонологическими ограничениями, чтобы оптимизировать сублексическое преобразование печатного текста в звуковой. Эти фонологические ограничения могут действовать на уровне отдельных фонем и фонологических слогов, как в CDP (Perry et al., 2010).
Орфография и морфология
Большое количество слов, которые мы читаем каждый день, являются морфологически сложными (примерно 75% во французском и 85% в английском языках). К ним относятся производные с приставками и суффиксами (например, "переделывать", "рабочий"), составные (например, "рабочее место") и флективные формы (например, "работы", "работающий", "работники"). Появляется все больше свидетельств того, что часть процесса чтения морфологически сложных слов включает в себя сублексическую сегментацию слова на составляющие его морфемы (например, work er). Большое количество исследований маскированного прайминга показало, что производные простые числа с суффиксами облегчают распознавание стволовых мишеней (worker–работа) по сравнению с несвязанными простыми числами (например, Grainger et al., 1991). Важно отметить, что морфологический прайминг превосходит как формальный прайминг (скандал–сканирование), так и семантический прайминг (жираф–лошадь; обзор см. в Diependaele et al., 2011). Однако, возможно, ключевое доказательство в пользу сублексической морфологической сегментации было получено в результате экспериментов с использованием семантически непрозрачных сложных простых чисел (отдел–depart) и псевдокомплексных простых чисел (corner–corn). Оба этих простых типа демонстрируют прайминг, аналогичный семантически прозрачным комплексным простым числам (worker–работа; обзор см. в Rastle and Davis, 2008), и значительно большую упрощенность, чем простые числа, состоящие из основы и окончания без суффикса (scandal–сканирование). Кроме того, аналогичные эффекты были также обнаружены при сравнении истинных производных простых слов (worker– работа) и сложных псевдосложных простых слов (cornity–кукуруза), в то время как, опять же, не было обнаружено затравки, когда простое образовано основой плюс окончание без суффикса (cornal-кукуруза; Лонгтин и Менье, 2005, но о возможных пределах такого вывода см. Morris et al., 2011).
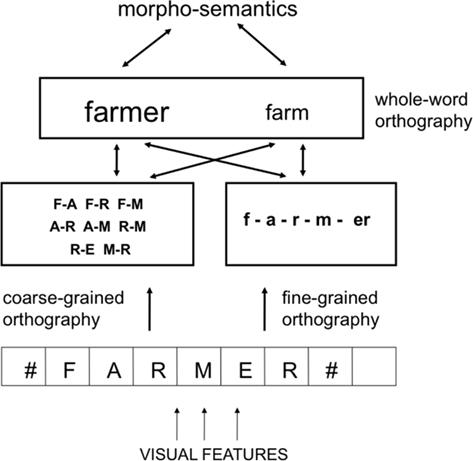
Рисунок 5. Морфологическая обработка и двухканальный подход к орфографической обработке. Мелкозернистая орфографическая обработка обеспечивает сублексическую морфо-орфографическую сегментацию с помощью определения аффиксов, таких как суффикс “er” в стимуле “фермер”. Активация в этих представлениях передается на орфографические представления целых слов, повышая уровень активации всех совместимых единиц (например, “фермер”, “ферма”). Грубая орфография активирует совместимые орфографические представления целых слов. Морфосемантические представления обеспечивают двунаправленную связь между представлениями целых слов, принадлежащими к одному и тому же морфологическому семейству.
На рисунке 5 показано, как подход к морфологической обработке, разработанный Diependaele и соавторами (2009), вписывается в наш двухсторонний подход к орфографической обработке. Морфо-орфографическая сегментация достигается с помощью мелкозернистой орфографической обработки, которая затем преобразует активацию в совместимые орфографические представления всего слова. В то же время крупнозернистая орфографическая обработка также приводит к прямой активации орфографических представлений целого слова, но независимо от морфологической структуры стимула. Активация в виде целых слов (как орфографических, так и фонологических, не показаны на рисунке 5) дополнительно ограничена нисходящей обратной связью от морфосемантических представлений, так что активация слова “фермер” приводит к повышенной активации слова “ферма” через общее морфосемантическое представление. о “чем-то, связанном с фермами”. Подводя итог, можно сказать, что ключевая идея, лежащая в основе нашего двухканального предложения применительно к морфологической обработке, заключается в том, что механизм, который распознает, что наличие буквы F где-то перед буквой R является хорошим признаком того, что обрабатываемое слово целиком является “фермером” или “фермерское хозяйство”, - это не тот же механизм, который распознает, что перед окончательным R стоит буква E, и что это сочетание набор букв выполняет определенную лингвистическую функцию.
Одно из предсказаний такого подхода к морфологической обработке в рамках многоуровневого подхода заключается в том, что эффекты, обусловленные морфо-орфографической обработкой, должны избирательно ослабляться манипуляциями, которые, как считается, в основном влияют на мелкозернистую орфографическую обработку. Это предсказание стало объектом недавнего эксперимента, в ходе которого мы сравнили влияние перестановок букв на прайминг при семантически прозрачных производных и псевдопроизводных. В этом исследовании стандартное сравнение морфологически прозрачных простых чисел (например, фермер– ферма) с псевдоморфологически родственными простыми числами (например, корнер - кукуруза) было дополнено манипуляцией с TL, включающей две буквы на границах морфемы (псевдоморфемы) (например, faremr – ферма; corenr-кукуруза). Эти эффекты прайминга были измерены относительно стандартных контрольных праймингов с двойной заменой (например, farivr–ферма; corivr–кукуруза).
Как и предсказывалось в соответствии с нашим теоретическим подходом, мы обнаружили значительный прирост от неповрежденных производных простых чисел (например, фермер–ферма) и производных от TL простых чисел (например, faremr–ферма), а также значительный прирост от неповрежденных псевдопроизводных простых чисел (например, corner-кукуруза), но, что наиболее важно, никакого прироста от TL псевдообразования (например, corenr–кукуруза). Согласно нашей двухпутевой модели, перестановки букв избирательно влияют на мелкозернистую орфографическую обработку и, следовательно, избирательно нарушают сублексическую морфо-орфографическую сегментацию. Поскольку предполагается, что это единственный источник прайминга для псевдопроизводных отношений (например, corner-corn), манипуляция TL устраняет прайминг в этом условии. С другой стороны, истинные морфологические отношения (например, фермер–фермерское хозяйство) все еще выигрывают от морфосемантического упрощения, получаемого с помощью крупнозернистого кодирования, так что простое “faremr” сильно активирует орфографическое представление всего слова “фермер”, которое соединяется с орфографическим представлением всего слова для слова “ферма” с помощью общих морфосемантических представлений.
Наконец, интересно отметить тот факт, что стандартные эффекты праймирования TL отсутствуют в семитских языках, по крайней мере, для истинно семитских слов этих языков (Velan and Frost, 2009, 2011; Perea et al., 2010). В рамках нашего двухстороннего подхода это означало бы, что семитские слова обрабатываются с помощью тщательной орфографической обработки, которая позволила бы точно определять корни с тремя согласными. Таким образом, перестановки букв нарушили бы обработку этих корневых морфем, причинив такой же ущерб, как и замены букв, из-за тонкой природы кодирования. Более того, Велан и Фрост (2011) недавно продемонстрировали, что морфологически простые еврейские слова несемитского происхождения демонстрируют стандартные эффекты перестановки букв, наблюдаемые в таких языках, как английский и французский. В рамках нашего двойного подхода эти несемитские слова на иврите будут обрабатываться точно так же, как английские и французские слова, с устойчивостью к манипуляциям с TL, обусловленной использованием метода грубой обработки. С другой стороны, слова, образованные от семитских корней, будут преимущественно обрабатываться мелкозернистым способом. Таким образом, ключевой вопрос здесь заключается в том, почему эти слова, происходящие от семитского корня, не будут также подвергаться крупнозернистой обработке, учитывая, что мы не ожидаем, что два маршрута обработки будут подвержены какому-либо механизму оперативного контроля, который мог бы отключить тот или иной маршрут обработки. Здесь мы предварительно предполагаем, что именно эффективность сопоставления формы и значения с помощью корневых морфем и глагольных паттернов в процессе детальной обработки (т.е. морфологической декомпозиции) предотвращает развитие крупнозернистой орфографической обработки (т.е. доступа ко всему слову) для семитских слов, образованных от корня, в процессе курс обучения чтению 6.
С точки зрения гипотезы Фроста (Frost, 2009) о том, что чтение слов в семитских языках включает в себя качественно иные процессы, чем те, которые используются для чтения слов в индоевропейских языках, в рамках нашей концепции двойного подхода это приводит к приоритету мелкозернистой обработки в отличие от крупнозернистой обработки. Как отмечалось выше, считается, что такая расстановка приоритетов не происходит в режиме онлайн, а возникает для каждого отдельного слова в зависимости от относительной эффективности процесса сопоставления орфографической информации с семантикой по каждому из двух путей. Таким образом, это скорее количественное, чем качественное различие, и в соответствии с этими рассуждениями Велан и Фрост (2011) сообщили о результатах интересного промежуточного анализа слов на иврите, которые имеют существующую глагольную структуру в сочетании с непродуктивным или псевдокорнем. Было обнаружено, что эти слова вызывают эффект прайминга, лежащий между словами, образованными от корня, и морфологически простыми несемитскими словами. В рамках нашего двухстороннего подхода, вероятно, сниженная эффективность морфо-орфографической обработки таких слов по сравнению со словами, образованными от корня, позволила бы развить крупнозернистую обработку, фактически не достигая того же уровня эффективности, который достигается при обработке несемитских слов крупнозернистым способом.
Пошаговый рассказ о том, как научиться читать слова
В заключительном разделе этой работы мы рассмотрим влияние нашего двухстороннего подхода к орфографической обработке на процесс обучения чтению слов. Это является существенным расширением подхода, учитывая, что два типа орфографического кодирования, постулируемые в нашей модели, как полагают, возникают в результате определенных ограничений, действующих при чтении. Поэтому важно начать понимать, как и когда могут проявляться такие ограничения и какие факторы могут влиять на их вклад в изучение орфографии.
Основная задача начинающего читателя, изучающего язык, использующий алфавитную письменность, состоит в том, чтобы связать идентичность букв со звуками, чтобы установить контакт с фонологическими представлениями известных слов в виде целых слов (фонологическое перекодирование). Первоначально это будет включать в себя стратегию последовательного чтения по буквам, поскольку механизм параллельного распознавания букв еще не разработан. Перемещая взгляд и внимание, начинающий читатель распознает разные буквы в слове по одной за раз и узнает, каким звукам они соответствуют. Этот механизм просто использует два ключевых источника информации, доступных начинающему читателю, – знание алфавита и разговорную лексику.
Помимо первоначального приобретения небольшого словарного запаса (включающего наиболее часто встречающиеся слова), мы согласны с Share (1995) и другими в том, что фонологическое кодирование является важным первым шагом в овладении чтением (например, Ehri, 1992). Вдохновленные гипотезой самообучения Share (1995), мы предполагаем, что именно во время этого относительно медленного и кропотливого процесса фонологической перекодировки воздействие печатных слов позволяет настроить специализированную систему для параллельной орфографической обработки, которая предполагается в нашей модели орфографической обработки. По словам Шара, каждое успешное расшифровывание, достигнутое с помощью кропотливой последовательной процедуры, дает начинающему читателю возможность установить связь между печатным словом и расшифрованным значением. В рамках данной теоретической базы это, в частности, предполагает разработку параллельной, независимой обработки букв. Именно разработка параллельной обработки букв, которая, как считается, включает в себя определенную форму буквенного кода, зависящего от местоположения, затем приводит к разработке двух типов сублексических орфографических кодов, которые формируют основу для квалифицированного чтения без слов в соответствии с нашим двухканальным подходом. Этот процесс развития проиллюстрирован на рисунке 6.
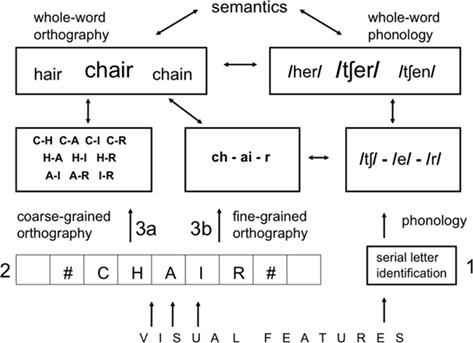
Рисунок 6. Основные этапы обучения чтению слов описаны в рамках многоуровневой модели беззвучного чтения. (1) Орфографический ввод сначала обрабатывается буква за буквой, а соответствующие звуки выводятся из букв и буквосочетаний (фонологическое перекодирование). (2) Разработка параллельной независимой обработки писем в виде банка детекторов писем, зависящих от местоположения. (3) Разработка двух типов сублексических представлений, не зависящих от местоположения: (а) крупнозернистых представлений для быстрого доступа к семантике из орфографии и (б) мелкозернистых представлений, включающих модификацию процесса, используемого для преобразования печатного текста в звуковой (графемные представления), и разработку морфо-- орфографические обозначения (аффиксы).
Предполагается, что природа двух типов сублексических орфографических кодов, не зависящих от местоположения, которые предполагаются в нашем подходе, определяется ограничениями, налагаемыми общей целью оптимизации сопоставления букв со значением при обучении чтению. С одной стороны, эти ограничения связаны с оптимизацией отображения букв в орфографических представлениях всего слова, а затем в связанных семантических представлениях. Это метод крупнозернистой обработки, который обеспечивает прямой доступ к семантике только с помощью орфографической информации. Здесь оптимизация, как полагают, предполагает разработку детекторов буквенных сочетаний, которые наилучшим образом определяют идентичность слов (ограничение диагностичности), точно так же, как части объектов выступают в качестве ключей к идентификации объектов в некоторых теоретических подходах к визуальному распознаванию объектов (например, Ullman et al., 2002). Для печатных слов мы предполагаем, что это включает в себя выбор буквосочетаний, которые максимально повышают видимость составляющих их букв и максимально увеличивают объем информации, которую они несут в отношении идентичности слова (Грейнджер и Дюфау, 2011).
Ограничения, возникающие при чтении, также помогают оптимизировать преобразование букв в значение, соединяя буквы с каналом, который уже используется для преобразования речи в значение при понимании устной речи. Это детализированный способ обработки, который обеспечивает доступ к семантике через фонологические и морфологические представления. Здесь предполагается, что оптимизация предполагает разработку орфографических представлений, которые облегчают сопоставление буквенных представлений с уже существующими сублексическими представлениями, участвующими в понимании произносимых слов7. Учитывая природу этих ранее существовавших представлений, предполагается, что эта оптимизация включает в себя обнаружение часто встречающихся буквенных сочетаний (ограничение на разбиение на фрагменты). Здесь ограничения действуют не для того, чтобы максимизировать информацию об идентичности слова, а для того, чтобы облегчить преобразование орфографического кода в другой тип лингвистического кода, который уже оптимизирован для отображения значения. Часто встречающиеся группы букв часто представляют собой орфографический эквивалент фонем и морфем.
Как отмечалось выше, считается, что процесс фонологического перекодирования изначально предполагает стратегию чтения по буквам, при которой информация о порядке обеспечивается последовательностью событий кодирования. Таким образом, предполагается, что развитие параллельной идентификации букв приведет к переходу от строго последовательного кодирования букв (которое выводит упорядоченный набор фонем) к более параллельному отображению букв в орфографические представления более высокого уровня, такие как графемы и аффиксы, которые сохраняют тот же уровень точности, что и строго последовательный механизм. (см. Alario et al., 2007). Становится ли отображение графем на фонемы более параллельным - это еще один вопрос, который все еще остается открытым для обсуждения (доказательства того, что этот процесс последователен на уровне представления слогов, см. в Carreiras et al., 2005). Здесь выдвигается гипотеза о том, что точная схема кодирования букв по центру слова позволяет разделять часто встречающиеся сочетания букв, такие как многобуквенные графемы и аффиксы, независимо от места фиксации взгляда в слове. Разработка параллельной версии этого детализированного орфографического кодирования особенно важна для извлечения суффиксов или рифм, для которых положение составляющих букв определяется относительно окончаний слов (например, Treiman et al., 1995).
Неконтролируемые алгоритмы обучения, такие как реализованные в самоорганизующихся картах (например, Кохонен, 1982; Дюфау и др., 2010) или теория адаптивного резонанса (например, Гроссберг, 1987; Глотин и др., 2010), предоставляют специальные механизмы для выполнения орфографического разбиения на блоки на основе параллельного ввода букв. В этих подходах частота встречаемости определяет формирование категорий более высокого порядка. Наконец, мы следуем за Zorzi et al., (1998) и Perry et al. (2007) предположили, что ассоциации, устанавливаемые между сублексическими орфографическими и фонологическими представлениями (такими как графемы и фонемы фонематического ряда), возникают в результате контролируемого обучения. Однако это наблюдение может осуществляться как извне (учителем), так и внутри организации, путем использования результатов побуквенной стратегии для изменения отображения параллельного орфографического кода на фонологический.
Более того, хотя изучение крупнозернистых и мелкозернистых представлений вполне может быть в значительной степени связано с неявными, неконтролируемыми алгоритмами обучения, внимание в этих двух случаях может играть разную роль. Недавние исследования показывают, что внимание может быть решающим фактором в изучении зависимостей между элементами (например, Пактон и Перруше, 2008; обзор фактических данных приведен в работе Ле Пелли, 2010). Согласно Пактону и Перруше (Pacton and Perruchet, 2008), причина, по которой несмежные непредвиденные обстоятельства обычно сложнее изучить, чем смежные непредвиденные обстоятельства, заключается в том, что легче сосредоточить внимание на смежных событиях, чем на несмежных событиях. В соответствии с этим рассуждением, примеры успешного изучения несмежных зависимостей включают ситуации, когда, возможно, легче обратить внимание на несмежные элементы (например, Gomez, 2002; Bonatti et al., 2005). В конкретном случае обучения чтению слов два фактора могут помочь сосредоточить внимание на непрерывных зависимостях между буквами. Одним из них может быть начальный этап обучения под наблюдением, когда начинающему читателю сообщают, что данная сложная графема соответствует определенной фонеме. Другой - это наличие уже существующих фонологических и/или морфологических представлений, которые соответствуют непрерывной последовательности букв. Пока что это хорошо для сочетаний смежных букв, но нам все еще нужно знать, как могут образовываться фрагменты несмежных букв, например, корневые морфемы семитских языков. Одна из возможностей здесь заключается в том, что различие между согласными и гласными (корни состоят исключительно из согласных) помогает сосредоточить внимание на этих несмежных элементах во время изучения разговорного языка, и что именно эта усвоенная ассоциация позволяет сосредоточить внимание на орфографическом эквиваленте во время обучения чтению.
Наш общий обзор обучения чтению слов, показанный на рисунке 6, предсказывает, что первоначальное преобладание последовательной фонологической перекодировки должно быстро смениться параллельной орфографической обработкой. Согласно этому отчету, разработка параллельной орфографической обработки позволит (1) ускорить доступ к семантическим представлениям за счет разработки крупнозернистого орфографического кода, (2) повысить эффективность сублингвального перевода орфографии в фонологию за счет разработки мелкозернистого орфографического кода и (3) появление как морфосемантических, так и морфоортографических представлений благодаря сочетанию крупнозернистой и мелкозернистой орфографической обработки. К числу эмпирических последствий развития параллельной орфографической обработки относятся: (1) уменьшение влияния длины слова (например, Агабабян и Назир, 2000; Биеляк-Бабич и др., 2004; Ача и Переа, 2008), (2) уменьшение фонологических эффектов, которые возникают главным образом из-за с помощью фонологической перекодировки (например, Sprenger-Charolles и др., 2003), (3) повышенной чувствительности к орфографической обработке (например, Castles и др., 2007; Acha и Perea, 2008) и (4) повышенной чувствительности к морфологической структуре (например, Colé и др., 2011). Будущие исследования должны обеспечить более детальный анализ этих различных закономерностей развития, а также конкретные тесты влияния нашей двухпутевой модели орфографической обработки на развитие чтения.
Два пути чтения в мозге?
Возникает соблазн связать наш функциональный двухканальный подход к обработке орфографических данных с часто проводимым различием между вентральными и дорсальными нейроанатомическими путями для чтения. Это предположение основано на аналогии с хорошо известным различием между вентральным (что) и дорсальным (где) путями обработки визуальных объектов. Несколько авторов сопоставили это классическое различие между вентральным и дорсальным путями с процессами, связанными с чтением слов, но это было сделано различными способами. Здесь мы кратко суммируем предыдущие описания этого отображения и обсуждаем, как их можно применить, чтобы выявить нейронные основы процессов, составляющих нашу модель с двумя маршрутами.
Один из подходов, предложенный в рамках стандартной теории двойного пути (Coltheart et al., 2001), заключается в том, чтобы связать вентральный путь с прямым отображением орфографии на семантику, а дорсальный путь - с отображением орфографии на фонологию (например, Pugh et al., 2000; Whitney and Корнелиссен, 2005; Боровски и др., 2006). Первое предложение реферата у Боровски и др. (2006) дает краткое описание этого подхода и свидетельствует о его популярности: “Большинство современных моделей нейрофизиологии базовых процессов чтения согласуются с системой, включающей два кортикальных потока: вентральный поток (затылочно–височный), используемый для доступа к знакомым словам, закодированным в лексической памяти, и дорсальный поток (затылочно-височный–теменно–лобный) используется при фонетическом расшифровывании слов (т.е. при преобразовании сублексического написания в звуки).” Это объяснение согласуется с данными о том, что мозговые структуры, расположенные на дорсальном пути, такие как супрамаргинальная извилина и угловая извилина, считается, что они участвуют в преобразовании орфографии в фонологию (например, Booth et al., 2003; Wilson et al., 2011), тогда как орфографическая обработка будет осуществляться структурами мозга в вентральных затылочно–височных областях (VOT) (например, Cohen et al., 2002).
References
Acha, J., and Perea, M. (2008). The effects of length and transposed-letter similarity in lexical decision: evidence with beginning, intermediate, and adult readers. Br. J. Psychol. 99, 245–264.
Acha, J., and Perea, M. (2010). Does kaniso activate CASINO? Input coding schemes and phonology in visual-word recognition. Exp. Psychol. 57, 245–251.
Aghababian, V., and Nazir, T. (2000). Developing normal reading skills: aspects of the visual processes underlying word recognition. J. Exp. Child Psychol. 76, 123–150.
Alario, F. X., De Cara, B., and Ziegler, J. C. (2007). Automatic activation of phonology in silent reading is parallel: evidence from beginning and skilled readers. J. Exp. Child Psychol. 97, 205–219.
Andrews, S. (1996). Lexical retrieval and selection processes: effects of transposed letter confusability. J. Mem. Lang. 35, 775–800.
Andrews, S., and Davis, C. J. (1999). Interactive activation accounts of morphological decomposition: finding the trap in mousetrap? Brain and Lang. 68, 355–361.
Bar, M., Kassam, K. S., Ghuman, A. S., Boshyan, J., Schmidt, A. M., Dale, A. M., Hamalainen, M. S., Marinkovic, K., Schacter, D. L., Rosen, B. R., and Halgren, E. (2006). Top-down facilitation of visual recognition. Proc. Natl. Acad. Sci. U.S.A. 103, 449–454.
Bick, A. S., Goelman, G., and Frost, R. (2011). Hebrew brain vs. English brain: language modulates the way it is processed. J. Cogn. Neurosci. doi: 10.1162/jocn.2010.21583.[Epub ahead of print].
Bijeljac-Babic, R., Millogo, V., Farioli, F., and Grainger, J. (2004). A developmental investigation of word length effects in reading using a new on-line word identification paradigm. Read. Writ. 17, 411–431.
Bonatti, L. L., Pena, M., Nespor, M., and Mehler, J. (2005). Linguistic constraints on statistical computations: the role of consonants and vowels in continuous speech processing. Psychol. Sci. 16, 451–459.
Booth, J. R., Burman, D. D., Meyer, J. R., Gitelman, D. R., Parrish, T. B., and Mesulam, M. M. (2003). Relation between brain activation and lexical performance. Hum. Brain Mapp. 19, 155–169.
Borowsky, R., Cummine, J., Owen, W. J., Friesen, C. K., Shih, F., and Sarty, G. E. (2006). FMRI of ventral and dorsal processing streams in basic reading processes: insular sensitivity to phonology. Brain Topogr. 18, 233–239.
Braun, M., Hutzler, F., Ziegler, J. C., Dambacher, M., and Jacobs, A. M. (2009). Pseudohomophone effects provide evidence of early lexico-phonological processing in visual word recognition. Hum. Brain Mapp. 30, 1977–1989.
Caramazza, A., and Hillis, A. E. (1990). Spatial representation of words in the brain implied by studies of a unilateral neglect patient. Nature 346, 267–269.
Carreiras, M., Ferrand, L., Grainger, J., and Perea, M. (2005). Sequential effects of masked phonological priming. Psychol. Sci. 16, 585–589.
Castles, A., Davis, C., Cavalot, P., and Forster, K. I. (2007). Tracking the acquisition of orthographic skills in developing readers: masked form priming and transposed-letter effects. J. Exp. Child Psychol. 97, 165–182.
Chambers, S. M. (1979). Letter and order information in lexical access. J. Verbal Learn. Behav. 18, 225–241.
Cohen, L., and Dehaene, S. (2009). “Ventral and dorsal contributions to word reading,” in The Cognitive Neuroscience, 4th Edn., ed. M. S. Gazzaniga (Cambridge, MA: MIT Press), 789–804.
Cohen, L., Dehaene, S., Vinckier, F., Jobert, A., and Montavont, A. (2008). Reading normal and degraded words: contribution of the dorsal and ventral visual pathways. Neuroimage 40, 353–366.
Cohen, L., Lehericy, S., Chochon, F., Lemer, C., Rivaud, S., and Dehaene, S. (2002). Language-specific tuning of visual cortex? Functional properties of the visual word form area. Brain 125, 1054–1069.
Colé, P., Bouton, S., Leuwers, C., Casalis, S., and Sprenger-Charolles, L. (2011). Stem and derivational suffix processing during reading by French second and third graders. Appl. Psycholinguist. (in press).
Coltheart, M., Curtis, B., Atkins, P., and Haller, M. (1993). Models of reading aloud – dual-route and parallel-distributed-processing approaches. Psychol. Rev. 100, 589–608.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., and Ziegler, J. C. (2001). DRC: a dual-route cascaded model of visual word recognition and reading aloud. Psychol. Rev. 108, 204–256.
Davis, C. J. (2010). The spatial coding model of visual word identification. Psychol. Rev. 117, 713–758.
Davis, M. H., and Rastle, K. (2010). Form and meaning in early morphological processing: comment on Feldman, O’Connor and Moscoso del Prado Martin. Psychon. Bull. Rev. 17, 749–755.
Dehaene, S., Cohen, L., Sigman, M., and Vinckier, F. (2005). The neural code for written words: a proposal. Trends Cogn. Sci. 9, 335–341.
Dehaene, S., Jobert, A., Naccache, L., Ciuciu, P., Poline, J. B., Le Bihan, D., and Cohen, L. (2004). Letter binding and invariant recognition of masked words. Psychol. Sci. 15, 307–313.
Diependaele, K., Grainger, J., and Sandra, D. (2011). “Derivational morphology and skilled reading: an empirical overview,” in The Cambridge Handbook of Psycholinguistics, eds M. Spivey, M. Joanisse, and K. McRae (Cambridge: Cambridge University Press).
Diependaele, K., Ziegler, J., and Grainger, J. (2010). Fast phonology and the bi-modal interactive activation model. Eur. J. Cogn. Psychol. 22, 764–778.
Diependaele, K., Sandra, D., and Grainger, J. (2005). Masked cross-modal morphological priming: unraveling morpho-orthographic and morpho-semantic influences in early word recognition. Lang. Cogn. Process. 20, 75–114.
Diependaele, K., Sandra, D., and Grainger, J. (2009). Semantic transparency and masked morphological priming: the case of prefixed words. Mem. Cogn. 37, 895–908.
Dufau, S., Lété, B., Touzet, C., Glotin, H., Ziegler, J., and Grainger, J. (2010). A developmental perspective on visual word recognition: new evidence and a self-organizing model. Eur. J. Cogn. Psychol. 22, 669–694.
Ehri, L. C. (1992). “Reconceptualizing the development of sight word reading and its relationship to recoding,” in Reading Acquisition, eds P. B. Gough, L. E. Ehri, and R. Treiman (Hillsdale, NJ: Lawrence Erlbaum Associates), 105–143.
Feldman, L. B., O’Connor, P. A., and Moscoso del Prado Martín, F. (2009). Early morphological processing is morphosemantic and not simply morpho-orthographic: a violation of form-then-meaning accounts of word recognition. Psychon. Bull. Rev. 16, 684–691.
Ferrand, L., and Grainger, J. (1994). Effects of orthography are independent of phonology in masked form priming. Q. J. Exp. Psychol. Hum. Exp. Psychol. 47A, 365–382.
Fischer-Baum, S., McCloskey, M., and Rapp, B. (2010). Representation of letter position in spelling: evidence from acquired dysgraphia. Cognition, 115, 466–490.
Frankish, C., and Barnes, L. (2008). Lexical and sublexical processes in the perception of transposed-letter anagrams. Q. J. Exp. Psychol. 61, 381–391.
Frankish, C., and Turner, E. (2007). SIHGT and SUNOD: the role of orthography and phonology in the perception of transposed letter anagrams. J. Mem. Lang. 56, 189–211.
Frost, R. (2009). “Reading in Hebrew vs. reading in English: is there a qualitative difference?” in How Children Learn to Read: Current Issues and New Directions in the Integration of Cognition, Neurobiology and Genetics of Reading and Dyslexia Research and Practice, eds K. Pugh, and P. McCradle (London: Psychology Press), 235–254.
Frost, R., Ahissar, M., Gotesman, R., and Tayeb, S. (2003). Are phonological effects fragile? The effect of luminance and exposure duration on form priming and phonological priming. J. Mem. Lang. 48, 346–378.
Giraudo, H., and Grainger, J. (2001). Priming complex words: evidence for supralexical representation of morphology. Psychon. Bull. Rev. 8, 127–131.
Glotin, H., Warnier, P., Dandurand, F., Dufau, S., Lété, B., Touzet, C., Ziegler, J., and Grainger, J. (2010). An adaptive resonance theory account of the implicit learning of orthographic word forms. J. Physiol. (Paris) 104, 19–26.
Gomez, P., Ratcliff, R., and Perea, M. (2008). The overlap model: a model of letter position coding. Psychol. Rev. 115, 577–601.
Goswami, U., and Ziegler, J. C. (2006). A developmental perspective on the neural code for written words. Trends Cogn. Sci. 10, 142–143.
Goswami, U., Ziegler, J. C., Dalton, L., and Schneider, W. (2001). Pseudohomophone effects and phonological recoding procedures in reading development in English and German. J. Mem. Lang. 45, 648–664.
Grainger, J. (2008). Cracking the orthographic code: an introduction. Lang. Cogn. Process. 23, 1–35.
Grainger, J., Colé, P., and Segui, J. (1991). Masked morphological priming in visual word recognition. J. Mem. Lang. 30, 370–384.
Grainger, J., Diependaele, K., Spinelli, E., Ferrand, L., and Farioli, F. (2003). Masked repetition and phonological priming within and across modalities. J. Exp. Psychol. Learn. Mem. Cogn. 29, 1256–1269.
Grainger, J., and Dufau, S. (2011). “The front-end of visual word recognition,” in Visual Word Recognition, Vol. 1: Models and Methods, Orthography and Phonology, ed. J. S. Adelman (Hove: Psychology Press).
Grainger, J., and Ferrand, L. (1994). Phonology and orthography in visual word recognition: effects of masked homophone primes. J. Mem. Lang. 33, 218–233.
Grainger, J., Granier, J. P., Farioli, F., Van Assche, E., and van Heuven, W. J. (2006a). Letter position information and printed word perception: the relative-position priming constraint. J. Exp. Psychol. Hum. Percept. Perform. 32, 865–884.
Grainger, J., Kiyonaga, K., and Holcomb, P. J. (2006b). The time-course of orthographic and phonological code activation. Psychol. Sci. 17, 1021–1026.
Grainger, J., and Holcomb, P. J. (2009). Watching the word go by: on the time-course of component processes in visual word recognition. Lang. Linguist. Compass 3, 128–156.
Grainger, J., and Jacobs, A. M. (1996). Orthographic processing in visual word recognition: a multiple read-out model. Psychol. Rev. 103, 518–565.
Grainger, J., and van Heuven, W. (2003). “Modeling letter position coding in printed word perception,” in The Mental Lexicon, ed. P. Bonin (New York: Nova Science Publishers), 1–24.
Grainger, J., and Whitney, C. (2004). Does the human mind read words as a whole? Trends Cogn. Sci. 8, 58–59.
Grainger, J., and Ziegler, J. (2008). “Cross-code consistency effects in visual word recognition,” in Single-Word Reading: Biological and Behavioral Perspectives, eds E. L. Grigorenko, and A. Naples (Mahwah, NJ: Lawrence Erlbaum Associates), 129–157.
Grossberg, S. (1987). Competitive learning: from interactive activation to adaptive resonance. Cogn. Sci. 11, 23–63.
Jacobs, A. M., and Grainger, J. (1994). Models of visual word recognition – sampling the state of the art. J. Exp. Psychol. Hum. Percept. Perform. 20, 1311–1334.
Jacobs, A. M., Rey, A., Ziegler, J. C., and Grainger, J. (1998). “MROM-P: an interactive activation, multiple read-out model of orthographic and phonological processes in visual word recognition,” in Localist Connectionist Approaches to Human Cognition, eds J. Grainger and A. M. Jacobs (Mahwah, NJ: Lawrence Erlbaum Associates), 147–188.
Jobard, G., Crivello, F., and Tzourio-Mazoyer, N. (2003). Evaluation of the dual route theory of reading: a metanalysis of 35 neuroimaging studies. Neuroimage 20, 693–712.
Kohonen, T. (1982). Self-organizing formation of topologically correct feature maps. Biol. Cybern. 43, 5969.
Le Pelley, M. E. (2010). “Attention and human associative learning,” in Associative Learning: From Brain to Behaviour, eds C. J. Mitchell and M. E. Le Pelley (Oxford: Oxford University Press), 187–216.
Longtin, C.-M., and Meunier, F. (2005). Morphological decomposition in early visual word processing. J. Mem. Lang. 53, 26–41.
Lukatela, G., and Turvey, M. T. (1994). Visual access is initially phonological: 2. Evidence from phonological priming by homophones, and pseudohomophones. J. Exp. Psychol. Gen. 123, 331–353.
McClelland, J. L., and Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: part 1. An account of basic findings. Psychol. Rev. 88, 375–407.
Mechelli, A., Crinion, J. T., Long, S., Friston, K. J., Lambon Ralph, M. A., Patterson, K., McClelland, J. L., and Price, C. J. (2005). Dissociating reading processes on the basis of neuronal interactions. J. Cogn. Neurosci. 17, 1753–1765.
Mel, B. W., and Fiser, J. (2000). Minimizing binding errors using learned conjunctive features. Neural Comput. 12, 731–762.
Morris, J., Frank, T., Grainger, J., and Holcomb, P. J. (2007). Semantic transparency and masked morphological priming: an ERP investigation. Psychophysiology 44, 506–521.
Morris, J., Porter, J. H., Grainger, J., and Holcomb, P. J. (2011). Effects of lexical status and morphological complexity in masked priming: an ERP study. Lang. Cogn. Process. (in press).
Mozer, M. C. (1987). “Early parallel processing in reading: A connectionist approach,” in Attention and performance XII: The Psychology of Reading ed. M. Coltheart (Hove, UK: Lawrence Erlbaum Associates Ltd.), 83–104.
O’Connor, R. E., and Forster, K. I. (1981). Criterion bias and search sequence bias in word recognition. Mem. Cogn. 9, 78–92.
Pacton, S., and Perruchet, P. (2008). An attention-based associative account of adjacent and non-adjacent dependency learning. J. Exp. Psychol. Lear. Mem. Cogn. 34, 80–96.
Perea, M., Abu Mallouh, R., and Carreiras, M. (2010). The search of an input coding scheme: transposed-letter priming in Arabic. Psychon. Bull. Rev. 17, 375–380.
Perea, M., and Lupker, S. J. (2004). Can CANISO activate CASINO? Transposed-letter similarity effects with nonadjacent letter positions. J. Mem. Lang. 51, 231–246.
Perea, M., Rosa, E., and Gomez, C. (2005). The frequency effect for pseudowords in the lexical decision task. Percept. Psychophys. 67, 301–314.
Peressotti, F., and Grainger, J. (1999). The role of letter identity and letter position in orthographic priming. Percept. Psychophys. 61, 691–706.
Perfetti, C. A., and Bell, L. (1991). Phonemic activation during the first 40 ms of word identification: evidence from backward masking and priming. J. Mem. Lang. 30, 473–485.
Perry, C., Ziegler, J. C., and Zorzi, M. (2007). Nested incremental modeling in the development of computational theories: the CDP model of reading aloud. Psychol. Rev. 114, 273–315.
Perry, C., Ziegler, J. C., and Zorzi, M. (2010). Beyond single syllables: large-scale modeling of reading aloud with the connectionist dual process (CDP ) model. Cogn. Psychol, 61, 106–151.
Plaut, D. C., McClelland, J. L., Seidenberg, M. S., and Patterson, K. (1996). Understanding normal and impaired word reading: computational principles in quasi-regular domains. Psychol. Rev. 103, 56–115.
Pugh, K. R., Mencl, W. E., Jenner, A. R., Katz, L., Frost, S. J., Lee, J. R., Shaywitz, S. A., and Shaywitz, B. A. (2000). Functional neuroimaging studies of reading and reading disability (developmental dyslexia). Ment. Retard Dev. Disabil. Res. Rev. 6, 207–213.
Rastle, K., and Brysbaert, M. (2006). Masked phonological priming effects in English: are they real? Do they matter? Cogn. Psychol. 53, 97–145.
Rastle, K., and Davis, M. H. (2008). Morphological decomposition based on the analysis of orthography. Lang. Cogn. Process. 23, 942–971.
Rosazza, C., Cai, Q., Minati, L., Paulignan, Y., and Nazir, T. A. (2009). Early involvement of dorsal and ventral pathways in visual word recognition: an ERP study. Brain Res. 1272, 32–44.
Sandak, R., Mencl, W. E., Frost, S. J., and Pugh, K. R. (2004). The neurobiological basis of skilled and impaired reading: recent findings and new directions. Sci. Stud. Read. 8, 273–292.
Schoonbaert, S., and Grainger, J. (2004). Letter position coding in printed word perception: effects of repeated and transposed letters. Lang. Cogn. Process. 19, 333–367.
Seidenberg, M. S., and McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychol. Rev. 96, 523–568.
Share, D. L. (1995). Phonological recoding and self-teaching: sine qua non of reading acquisition. Cognition 55, 151–218.
Solomyak, O., and Marantz, A. (2009). Evidence for early morphological decomposition in visual word recognition. J. Cogn. Neurosci. 22, 2042–2057.
Sprenger-Charolles, L., Siegel, L. S., Béchennec, D., and Serniclaes, W. (2003). Development of phonological and orthographic processing in reading aloud, in silent reading, and in spelling: A longitudinal study. J. Exp. Child Psychol. 84, 194–217.
Stevens, M., and Grainger, J. (2003). Letter visibility and the viewing position effect in visual word recognition. Percept. Psychophys. 65, 133–151.
Treiman, R., Mullennix, J., Bijeljac-Babic, R., and Richmond-Welty, E. D. (1995). The special role of rimes in the description, use, and acquisition of English orthography. J. Exp. Psychol. Gen. 124, 107–136.
Ullman, S., Vidal-Naquet, M., and Sali, E. (2002). Visual features of intermediate complexity and their use in classification. Nat. Neurosci. 5, 682–687.
Van Assche, E., and Grainger, J. (2006). A study of relative-position priming with superset primes. J. Exp. Psychol. Learn. Mem. Cogn. 32, 399–415.
Velan, H., and Frost, R. (2009). Letter-transposition effects are not universal: the impact of transposing letters in Hebrew. J. Mem. Lang. 61, 285–302.
Velan, H., and Frost, R. (2011). Words with and without internal structure: what determines the nature of orthographic and morphological processing? Cognition 118, 141–156.
Vinckier, F., Dehaene, S., Jobert, A., Dubus, J. P., Sigman, M., and Cohen, L. (2007). Hierarchical coding of letter strings in the ventral stream: dissecting the inner organization of the visual word-form system. Neuron 55, 143–156.
von der Malsburg, C. (1999). The what and why of binding: the modeler’s perspective. Neuron 24, 95–104.
Welvaert, M., Farioli, F., and Grainger, J. (2008). Graded effects of number of inserted letters in superset priming. Exp. Psychol. 55, 54–63.
Wheat, K. L., Cornelissen, P. L., Frost, S. J., and Hansen, P.C. (2010). During visual word recognition, phonology is accessed within 100 ms and may be mediated by a speed production code: evidence from magnetoencephalography. J. Neurosci. 30, 5229–5233.
Whitney, C. (2001). How the brain encodes the order of letters in a printed word: the SERIOL model and selective literature review. Psychon. Bull. Rev. 8, 221–243.
Whitney, C., and Cornelissen, P. (2005). Letter-position encoding and dyslexia. J. Res. Read. 28, 274–301.
Wilson, L. B., Tregallas, J. R., Slason, E., Pasko, B. E., and Rojas, D. C. (2011). Implicit phonological priming during visual word recognition. Neuroimage 55, 724–731.
Ziegler, J. C., Ferrand, L., Jacobs, A. M., Rey, A., and Grainger, J. (2000). Visual and phonological codes in letter and word recognition: evidence from incremental priming. Q. J. Exp. Psychol. Hum. Exp. Psychol. 53A, 671–692.
Ziegler, J. C., and Goswami, U. (2005). Reading acquisition, developmental dyslexia, and skilled reading across languages: a psycholinguistic grain size theory. Psychol. Bull. 131, 3–29.
Ziegler, J. C., Jacobs, A. M., and Klueppel, D. (2001). Pseudohomophone effects in lexical decision: still a challenge for current word recognition models. J. Exp. Psychol. Hum. Percept. Perform. 27, 547–559.
Zorzi, M. (2010). The connectionist dual process (CDP) approach to modelling reading aloud. Eur. J. Cogn. Psychol. 22, 836–860.
Zorzi, M., Houghton, G., and Butterworth, B. (1998). Two routes or one in reading aloud? A connectionist dual-process model. J. Exp. Psychol. Hum. Percept. Perform. 24, 1131–1161.
Последнее редактирование: 18.06.2025
Чтобы оставить комментарии нужно авторизоваться.