Байесовская фильтрация спама
Байесовская фильтрация спама
http://intellect.ml/bajesovskaya-filtratsiya-spama-4749/
В качестве введения
В настоящее время Байесовские методы получили достаточно широкое распространение и активно используются в самых различных областях знаний. Однако, к сожалению, не так много людей имеют представление о том, что же это такое и зачем это нужно. Одной из причин является отсутствие большого количества литературы на русском языке. Поэтому здесь попытаюсь изложить их принципы настолько просто, насколько смогу, начав с самых азов (прошу прощения, если кому-то это покажется слишком простым).
В дальнейшем я бы хотел перейти к непосредственно Байесовскому анализу и рассказать об обработке реальных данных и о, на мой взгляд, отличной альтернативе языку R (о нем немного писалось тут) — Python с модулем pymc. Лично мне Python кажется гораздо более понятным и логичным, чем R с пакетами JAGS и BUGS, к тому же Python дает гораздо большую свободу и гибкость (хотя в Python есть и свои трудности, но они преодолимы, да и в простом анализе встречаются нечасто).
Немного истории
В качестве краткой исторической справки скажу, что формула Байеса была опубликована аж в 1763 году спустя 2 года после смерти ее автора, Томаса Байеса. Однако, методы, использующие ее, получили действительно широкое распространение только к концу ХХ века. Это объясняется тем, что расчеты требуют определенных вычислительных затрат, и они стали возможны только с развитием информационных технологий.
О вероятности и теореме Байеса
Формула Байеса и все последующее изложение требует понимания вероятности. Подробнее о вероятности можно почитать на Википедии.
На практике вероятность наступления события есть частота наступления этого события, то есть отношение количества наблюдений события к общему количеству наблюдений при большом (теоретически бесконечном) общем количестве наблюдений.
Рассмотрим следующий эксперимент: мы называем любое число из отрезка [0, 1] и смотрим за тем, что это число будет между, например, 0.1 и 0.4. Как нетрудно догадаться, вероятность этого события будет равна отношению длины отрезка [0.1, 0.4] к общей длине отрезка [0, 1] (другими словами, отношение «количества» возможных равновероятных значений к общему «количеству» значений), то есть (0.4 — 0.1) / (1 — 0) = 0.3, то есть вероятность попадания в отрезок [0.1, 0.4] равна 30%.
Теперь посмотрим на квадрат [0, 1] x [0, 1].
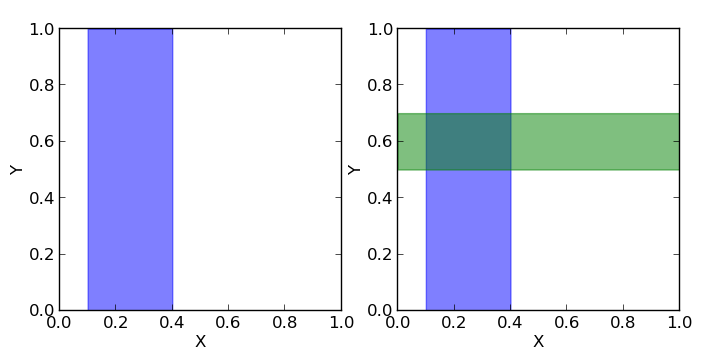
Допустим, мы должны называть пары чисел (x, y), каждое из которых больше нуля и меньше единицы. Вероятность того, что x (первое число) будет в пределах отрезка [0.1, 0.4] (показан на первом рисунке как синяя область, на данный момент для нас второе число y не важно), равна отношению площади синей области к площади всего квадрата, то есть (0.4 — 0.1) * (1 — 0) / (1 * 1) = 0.3, то есть 30%. Таким образом можно записать, что вероятность того, что x принадлежит отрезку [0.1, 0.4] равна p(0.1 <= x <= 0.4) = 0.3 или для краткости p(X) = 0.3.
Если мы теперь посмотрим на y, то, аналогично, вероятность того, что y находится внутри отрезка [0.5, 0.7] равна отношению площади зеленой области к площади всего квадрата p(0.5 <= y <= 0.7) = 0.2, или для краткости p(Y) = 0.2.
Теперь посмотрим, что можно узнать о значениях одновременно x и y.
Если мы хотим знать, какова вероятность того, что одновременно x и y находятся в соответствующих заданных отрезках, то нам нужно посчитать отношение темной площади (пересечения зеленой и синей областей) к площади всего квадрата: p(X, Y) = (0.4 — 0.1) * (0.7 — 0.5) / (1 * 1) = 0.06.
А теперь допустим мы хотим знать какова вероятность того, что y находится в интервале [0.5, 0.7], если x уже находится в интервале [0.1, 0.4]. То есть фактически у нас есть фильтр и когда мы называем пары (x, y), то мы сразу отбрасывает те пары, которые не удовлетворяют условию нахождения x в заданном интервале, а потом из отфильтрованных пар мы считаем те, для которых y удовлетворяет нашему условию и считаем вероятность как отношение количества пар, для которых y лежит в вышеупомянутом отрезке к общему количеству отфильтрованных пар (то есть для которых x лежит в отрезке [0.1, 0.4]). Мы можем записать эту вероятность как p(Y|X). Очевидно, что эта вероятность равна отношению площади темной области (пересечение зеленой и синей областей) к площади синей области. Площадь темной области равна (0.4 — 0.1) * (0.7 — 0.5) = 0.06, а площадь синей (0.4 — 0.1) * (1 — 0) = 0.3, тогда их отношение равно 0.06 / 0.3 = 0.2. Другими словами, вероятность нахождения y на отрезке [0.5, 0.7] при том, что x уже принадлежит отрезку [0.1, 0.4] равна p(Y|X) = 0.2.
Можно заметить, что с учетом всего вышесказанного и всех приведенных выше обозначений, мы можем написать следующее выражение
p(Y|X) = p(X, Y) / p(X)
Кратко воспроизведем всю предыдущую логику теперь по отношению к p(X|Y): мы называем пары (x, y) и фильтруем те, для которых y лежит между 0.5 и 0.7, тогда вероятность того, что x находится в отрезке [0.1, 0.4] при условии, что y принадлежит отрезку [0.5, 0.7] равна отношению площади темной области к площади зеленой:
p(X|Y) = p(X, Y) / p(Y)
В двух приведенных выше формулах мы видим, что член p(X, Y) одинаков, и мы можем его исключить:
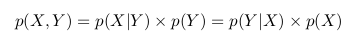
Мы можем переписать последнее равенство как
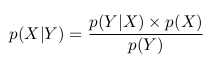
Это и есть теорема Байеса.
Интересно еще заметить, что p(Y) это фактически p(X,Y) при всех значениях X. То есть, если мы возьмем темную область и растянем ее так, что она будет покрывать все значения X, она будет в точности повторять зеленую область, а значит, она будет равна p(Y). На языке математики это будет означать следующее:
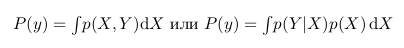
Тогда мы можем переписать формулу Байеса в следующем виде:
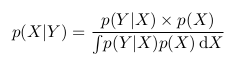
Применение теоремы Байеса
Давайте рассмотрим следующий пример. Возьмем монетку и подкинем ее 3 раза. С одинаковой вероятностью мы можем получить следующие результаты (О — орел, Р — решка): ООО, ООР, ОРО, ОРР, РОО, РОР, РРО, РРР.
Мы можем посчитать какое количество орлов выпало в каждом случае и сколько при этом было смен орел-решка, решка-орел: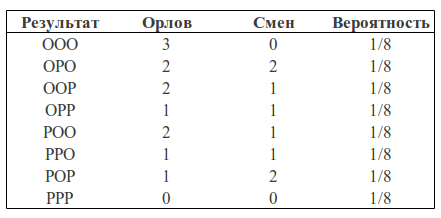
Мы можем рассматривать количество орлов и количество изменений как две случайные величины. Тогда таблица вероятностей будет иметь следуюший вид: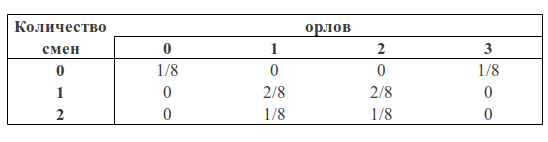
Теперь мы можем увидеть формулу Байеса в действии.
Но прежде проведем аналогию с квадратом, который мы рассматривали ранее.
Можно заметить, что p(1O) есть сумма третьего столбца («синяя область» квадрата) и равна сумме всех значений ячеек в этом столбце: p(1O) = 2/8 + 1/8 = 3/8
p(1С) есть сумма третьей строки («зеленая область» квадрата) и, аналогично, равна сумме всех значений ячеек в этой строке p(1С) = 2/8 + 2/8 = 4/8
Вероятность того, что мы получили одного орла и одну смену равна пересечению этих областей (то есть значение в клетке пересечения третьего столбца и третьей строки) p(1С, 1О) = 2/8
Тогда, следуя формулам описанным выше, мы можем посчитать вероятность получить одну смену, если мы получили одного орла в трех бросках:
p(1С|1О) = p(1С, 1О) / p(1О) = (2/8) / (3/8) = 2/3
или вероятность получить одного орла, если мы получили одну смену:
p(1О|1С) = p(1С, 1О) / p(1С) = (2/8) / (4/8) = 1/2
Если мы посчитаем вероятность получить одну смену при наличии одного орла p(1О|1С) через формулу Байеса, то получим:
p(1О|1С) = p(1С|1О) * p(1О) / p(1С) = (2/3) * (3/8) / (4/8) = 1/2
Что мы и получили выше.
Но какое практическое значение имеет приведенный выше пример?
Дело в том, что, когда мы анализируем реальные данные, обычно нас интересует какой-то параметр этих данных (например, среднее, дисперсия и пр.). Тогда мы можем провести следующую аналогию с вышеприведенной таблицей вероятностей: пусть строки будут нашими экспериментальными данными (обозначим их Data), а столбцы — возможными значениями интересующего нас параметра этих данных (обозначим его 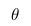 ). Тогда нас интересует вероятность получить определенное значение параметра на основе имеющихся данных
). Тогда нас интересует вероятность получить определенное значение параметра на основе имеющихся данных 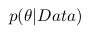 .
.
Мы можем применить формулу Баейса и записать следующее: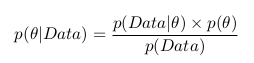
А вспомнив формулу с интегралом, можно записать следующее: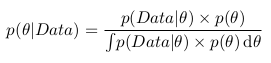
То есть фактически как результат нашего анализа мы имеет вероятность как функцию параметра. Теперь мы можем, например, максимизировать эту функцию и найти наиболее вероятное значение параметра, посчитать дисперсию и среднее значение параметра, посчитать границы отрезка, внутри которого интересующий нас параметр лежит с вероятностью 95% и пр.
Вероятность называют апостериорной вероятностью. И для того, чтобы посчитать ее нам надо иметь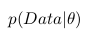 — функцию правдоподобия и
— функцию правдоподобия и 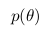 — априорную вероятность.
— априорную вероятность.
Функция правдоподобия определяется нашей моделью. То есть мы создаем модель сбора данных, которая зависит от интересующего нас параметра. К примеру, мы хотим интерполировать данные с помощью прямой y = a * x + b (таким образом мы предполагаем, что все данные имеют линейную зависимость с наложенным на нее гауссовым шумом с известной дисперсией). Тогда a и b — это наши параметры, и мы хотим узнать их наиболее вероятные значения, а функция правдоподобия — гаусс со средним, заданным уравнением прямой, и данной дисперсией.
Априорная вероятность включает в себя информацию, которую мы знаем до проведения анализа. Например, мы точно знаем, что прямая должна иметь положительный наклон, или, что значение в точке пересечения с осью x должно быть положительным, — все это и не только мы можем инкорпорировать в наш анализ.
Как можно заметить, знаменатель дроби является интегралом (или в случае, когда параметры могут принимать только определенные дискретные значения, суммой) числителя по всем возможным значениям параметра. Практически это означает, что знаменатель является константой и служит для того, что нормализировать апостериорную вероятность (то есть, чтобы интеграл апостериорной вероятности был равен единице).
Этот пост является логическим продолжением моего первого поста о Байесовских методах, который можно найти тут.
Я бы хотел подробно рассказать о том, как проводить анализ на практике.
Как я уже упоминал, наиболее популярным средством, используемым для Байесовского анализа, является язык R с пакетами JAGS и/или BUGS. Для рядового пользователя различие в пакетах состоит в кросс-платформенности JAGS (на собственном опыте убедился в наличии конфликта между Ubuntu и BUGS), а также в том, что в JAGS можно создавать свои функции и распределения (впрочем, необходимость в этом у рядового пользователя возникает нечасто, если вообще возникает). Кстати, отличным и удобным IDE для R является, например, RStudio.
Но в этом посте я напишу об альтернативе R — Python с модулем pymc.
В качестве удобного IDE для Python могу предложить spyder.
Я отдаю предпочтение Python потому, что, во-первых, не вижу смысла изучать такой не слишком распространенный язык, как R, только для того, чтобы посчитать какую-то задачку, касающуюся статистики. Во-вторых, Python с его модулями, с моей точки зрения, ничем не уступает R в простоте, понятности и функциональности.
Я предлагаю решить простую задачу нахождения коэффициентов линейной зависимости данных. Подобная задача оптимизации параметров довольно часто встречается в самых разных областях знаний, поэтому я бы сказал, что она весьма показательна. В конце мы сможем сравнить результат Байесовского анализа и метода наименьших квадратов
Установка ПО
Прежде всего нам надо установить Python (для тех, кто этого еще не сделал). Я не пользовался Python 3.3, но с 2.7 все точно работает.
Затем нужно установить все необходимые модули для Python: numpy, Matplotlib.
При желании вы можете также установить дополнительные модули: scipy, pyTables, pydot, IPython и nose.
Все эти установки (кроме самого Python) проще делать через setuptools.
А теперь можно установить собственно pymc (его можно также поставить через setuptools).
Подробный гайд по pymc можно найти тут.
Формулировка задачи
У нас есть данные, полученные в ходе гипотетического эксперимента, которые линейно зависят от некоторой величины x. Данные поступают с шумом, дисперсия которого неизвестна. Необходимо найти коэффициенты линейной зависимости.
Решение
Сперва мы импортируем модули, которые мы установили, и которые нам понадобятся:
import numpy
import pymc
Затем нам надо получить наши гипотетические линейные данные.
Для этого мы определяем, какое количество точек мы хотим иметь (в данном случае 20), они равномерно распределены на отрезке [0, 10], и задаем реальные коэффициенты линейной зависимости. Далее мы накладываем на данные гауссов шум:
#Generate data with noise
number_points = 20
true_coefficients = [10.4, 5.5]
x = numpy.linspace(0, 10, number_points)
noise = numpy.random.normal(size = number_points)
data = true_coefficients[0]*x + true_coefficients[1] + noise
Итак, у нас есть данные, и теперь нам надо подумать, как мы хотим проводить анализ.
Во-первых, мы знаем (или предполагаем), что наш шум гауссов, значит, функция правдоподобия у нас будет гауссова. У нее есть два параметра: среднее и дисперсия. Так как среднее шума равно нулю, то среднее для функции правдоподобия будет задаваться значением модели (а модель у нас линейная, поэтому там два параметра). Тогда как дисперсия нам неизвестна, следовательно, она будет еще одним параметром.
В результате у нас есть три параметра и гауссова функция правдоподобия.
Мы ничего не знаем о значениях параметров, поэтому a priori предположим их равномерно распределенными с произвольными границами (эти границы можно отодвигать сколь угодно далеко).
При задании априорного распределения, мы должны указать метку, по которой мы будем узнавать об апостериорных значениях параметров (первый аргумент), а также указать границы распределения (второй и третий аргументы). Все вышеперечисленные аргументы являются обязательными (еще есть дополнительные аргументы, описание которых можно найти в документации).
sigma = pymc.Uniform('sigma', 0., 100.)
a = pymc.Uniform('a', 0., 20.)
b = pymc.Uniform('b', 0., 20.)
Теперь надо задать нашу модель. В pymc сушествует два наиболее часто используемых класса: детерминистический и стохастический. Если при заданных входных данных можно однозначно определить значение(-я), которое(-ые) модель возвращает, значит, это детерминистическая модель. В нашем случае при заданных коэффициентах линейной зависимости для любой точки мы можем однозначно определить результат, соответственно это детерминистическая модель:
@pymc.deterministic(plot=False)
def linear_fit(a=a, b=b, x=x):
return a*x + b
И наконец задаем функцию правдоподобия, в которой среднее — это значение модели, sigma — параметр с заданным априорным распределением, а data — это наши экспериментальные данные:
y = pymc.Normal('y', mu=linear_fit, tau=1.0/sigma**2, value=data, observed=True)
Итак, весь файл model.py выглядит следующим образом:
import numpy
import pymc
#Generate data with noise
number_points = 20
true_coefficients = [10.4, 5.5]
x = numpy.linspace(0, 10, number_points)
noise = numpy.random.normal(size = number_points)
data = true_coefficients[0]*x + true_coefficients[1] + noise
#PRIORs:
#as sigma is unknown then we define it as a parameter:
sigma = pymc.Uniform('sigma', 0., 100.)
#fitting the line y = a*x+b, hence the coefficient are parameters:
a = pymc.Uniform('a', 0., 20.)
b = pymc.Uniform('b', 0., 20.)
#define the model: if a, b and x are given the return value is determined, hence the model is deterministic:
@pymc.deterministic(plot=False)
def linear_fit(a=a, b=b, x=x):
return a*x + b
#LIKELIHOOD
#normal likelihood with observed data (with noise), model value and sigma
y = pymc.Normal('y', mu=linear_fit, tau=1.0/sigma**2, value=data, observed=True)
Теперь я предлагаю сделать небольшое теоретическое отступление и обсудить, что же все-таки делает pymc.
С точки зрения матеметики, нам нужно решить следующую задачу:
p(a, b, sigma | Data) = p(Data | a, b, sigma)*p(a, b, sigma) / p(Data)
Т.к. a, b и sigma независимы, то мы можем переписать уравнение в следующем виде:
p(a, b, sigma | Data) = p(Data | a, b, sigma)*p(a)*p( b)*p(sigma) / p(Data)
На бумаге задача выглядит очень просто, но, когда мы ее решаем численно (при этом мы должны думать еще и о том, что мы хотим численно решить любую задачу такого класса, а не только с определенными типами вероятностей), то тут возникают трудности.
p(Data) — это, как обсуждалось в моем предыдущем посте, константа.
p(Data | a, b, sigma) нам определенно задана (то есть при известных a, b и sigma мы можем однозначно рассчитать вероятности для наших имеющихся данных)
a вот вместо p(a), p( b) и p(sigma) у нас, по сути, имеются только генераторы псевдослучайных величин, распределенных по заданному нами закону.
Как из всего этого получить апостериорное распределение? Правильно, генерировать (делать выборку) a, b и sigma, а потом считать p(Data | a, b, sigma). В результате у нас получится цепочка значений, которая является выборкой из апостериорного распределения. Но тут возникает вопрос, каким образом мы можем сделать эту выборку правильно. Если наше апостериорное распределение имеет несколько мод («холмов»), то как можно сгенерировать выборку, покрывающую все моды. То есть задача в том, как эффективно сделать выборку, которая бы «покрывала» все распределение за наименьшее количество итераций. Для этого есть несколько алгоритмов, наиболее используемый из которых MCMC (Markov chain Monte Carlo). Цепь Маркова — это такая последовательность случайных событий, в которой каждый элемент зависит от предыдущего, но не зависит от предпредыдущего. Я не стану описывать сам алгоритм (это может быть темой отдельного поста), но только отмечу, что pymc реализует этот алгоритм и в качестве результата дает цепь Маркова, являющуюся выборкой из апостериорного распределения. Вообще говоря, если мы не хотим, чтобы цепь была марковской, то нам просто надо ее «утоньшить», т.е. брать, например, каждый второй элемент.
Итак, мы создаем второй файл, назовем его run_model.py, в котором будем генерировать цепь Маркова. Файлы model.py и run_model.py должны быть в одной папке, иначе в файл run_model.py нужно добавить код:
from sys import path
path.append("путь/к/папке/с/файлом/model.py/")
Вначале мы импортируем некоторые модули, которые нам пригодятся:
from numpy import polyfit
from matplotlib.pyplot import figure, plot, show, legend
import pymc
import model
polyfit реализует метод наименьших квадратов — с ним мы сравним результаты байесовского анализа.
figure, plot, show, legend нужны для того, чтобы построить итоговый график.
model — это, собственно, наша модель.
Затем мы создаем MCMC объект и запускаем выборку:
D = pymc.MCMC(model, db = 'pickle')
D.sample(iter = 10000, burn = 1000)
D.sample принимает два аргумента (на самом деле можно задать больше) — количество итераций и burn-in (назовем его «периодом разогрева»). Период разогрева — это количество первых итераций, которые обрезаются. Дело в том, что MCMC вначале зависит от стартовой точки (вот такое уж свойство), поэтому нам необходимо отрезать этот период зависимости.
На этом наш анализ закончен.
Теперь у нас есть объект D, в котором находится выборка, и который имеет различные методы (функции), позволяющие рассчитать параметры этой выборки (среднее, наиболее вероятное значение, дисперсию и пр.).
Для того, чтобы сравнить результаты, мы делаем анализ методом наименьших квадратов:
chisq_result = polyfit(model.x, model.data, 1)
Теперь печатаем все результаты:
print "
Result of chi-square result: a= %f, b= %f" % (chisq_result[0], chisq_result[1])
print "
Result of Bayesian analysis: a= %f, b= %f" % (D.a.value, D.b.value)
print "
The real coefficients are: a= %f, b= %f
" %(model.true_coefficients[0], model.true_coefficients[1])
Строим стандартные для pymc графики:
pymc.Matplot.plot(D)
И, наконец, строим наш итоговый график:
figure()
plot(model.x, model.data, marker='+', linestyle='')
plot(model.x, D.a.value * model.x + D.b.value, color='g', label='Bayes')
plot(model.x, chisq_result[0] * model.x + chisq_result[1], color='r', label='Chi-squared')
plot(model.x, model.true_coefficients[0] * model.x + model.true_coefficients[1], color='k', label='Data')
legend()
show()
Вот полное содержание файла run_model.py:
from numpy import polyfit
from matplotlib.pyplot import figure, plot, show, legend
import pymc
import model
#Define MCMC:
D = pymc.MCMC(model, db = 'pickle')
#Sample MCMC: 10000 iterations, burn-in period is 1000
D.sample(iter = 10000, burn = 1000)
#compute chi-squared fitting for comparison:
chisq_result = polyfit(model.x, model.data, 1)
#print the results:
print "
Result of chi-square result: a= %f, b= %f" % (chisq_result[0], chisq_result[1])
print "
Result of Bayesian analysis: a= %f, b= %f" % (D.a.value, D.b.value)
print "
The real coefficients are: a= %f, b= %f
" %(model.true_coefficients[0], model.true_coefficients[1])
#plot graphs from MCMC:
pymc.Matplot.plot(D)
#plot noised data, true line and two fitted lines (bayes and chi-squared):
figure()
plot(model.x, model.data, marker='+', linestyle='')
plot(model.x, D.a.value * model.x + D.b.value, color='g', label='Bayes')
plot(model.x, chisq_result[0] * model.x + chisq_result[1], color='r', label='Chi-squared')
plot(model.x, model.true_coefficients[0] * model.x + model.true_coefficients[1], color='k', label='Data')
legend()
show()
В терминале мы видим следующий ответ:
Result of chi-square result: a= 10.321533, b= 6.307100
Result of Bayesian analysis: a= 10.366272, b= 6.068982
The real coefficients are: a= 10.400000, b= 5.500000
Замечу, что, так как мы имеет дело со случайным процессом, те значения, которые вы увидите у себя, могут отличаться от вышеприведенных (кроме последней строки).
А в папке с файлом run_model.py мы увидим следующие графики.
Для параметра a: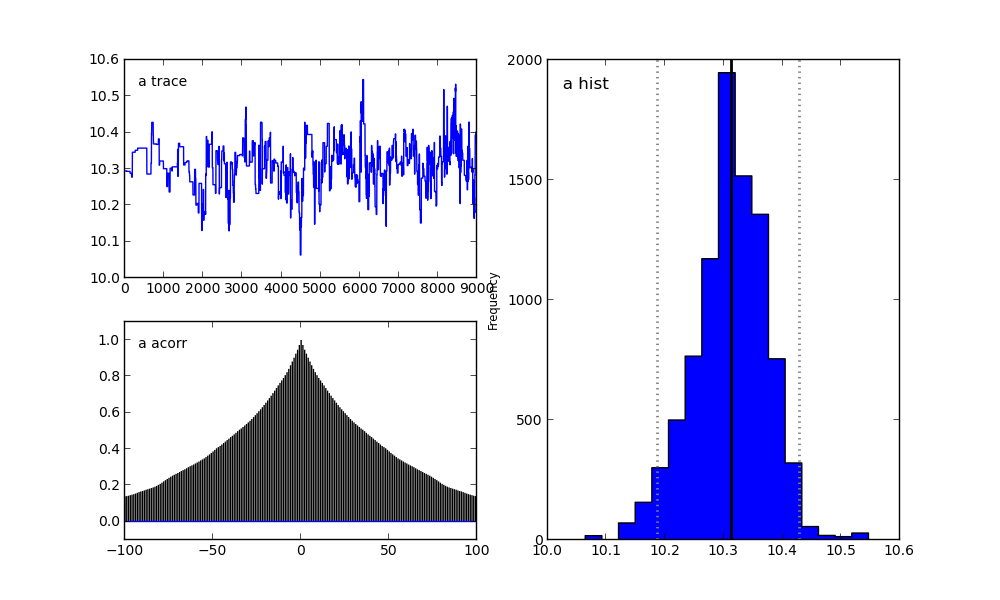
Для параметра b: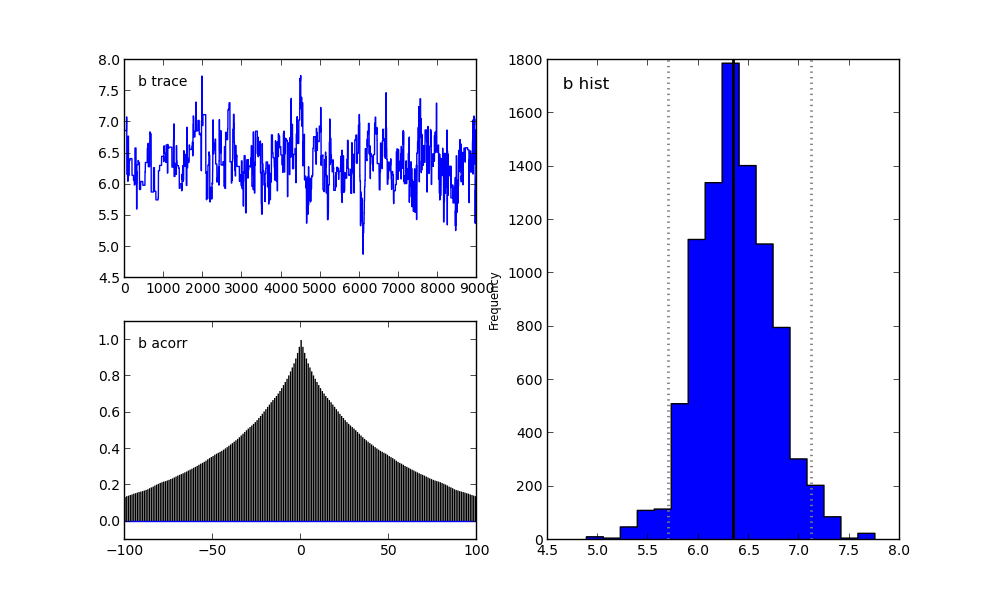
Для параметра sigma: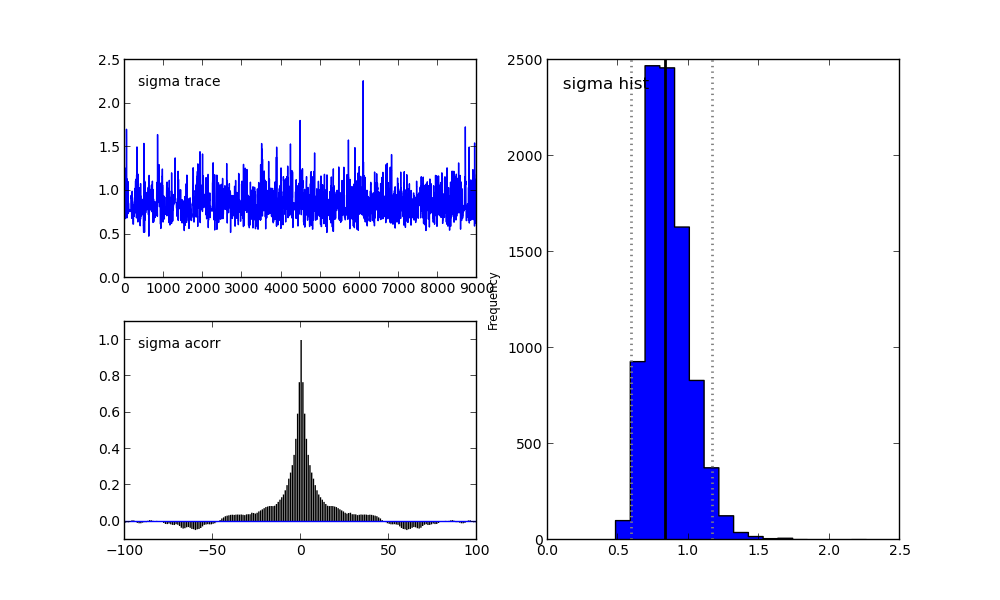
Справа мы видим гистограмму апостериорного распределения, а две картинки слева относятся к цепи Маркова.
На них я сейчас заострять внимание не буду. Скажу лишь, что нижний график — это график автокорреляции (подробнее можно прочитать тут). Он дает представление о сходимости MCMC.
А верхний график показывает след выборки. То есть он показывает, каким образом происходила выборка с течением времени. Среднее этого следа есть среднее выборки (сравните вертикальную ось на этом графике с горизонтальной осью на гистограмме справа).
В заключение я расскажу еще об одной интересной опции.
Если все же поставить модуль pydot и в файл run_model.py включить следующую строку:
pymc.graph.dag(D).write_png('dag.png')
То он создаст в папке с файлом run_model.py следующий рисунок: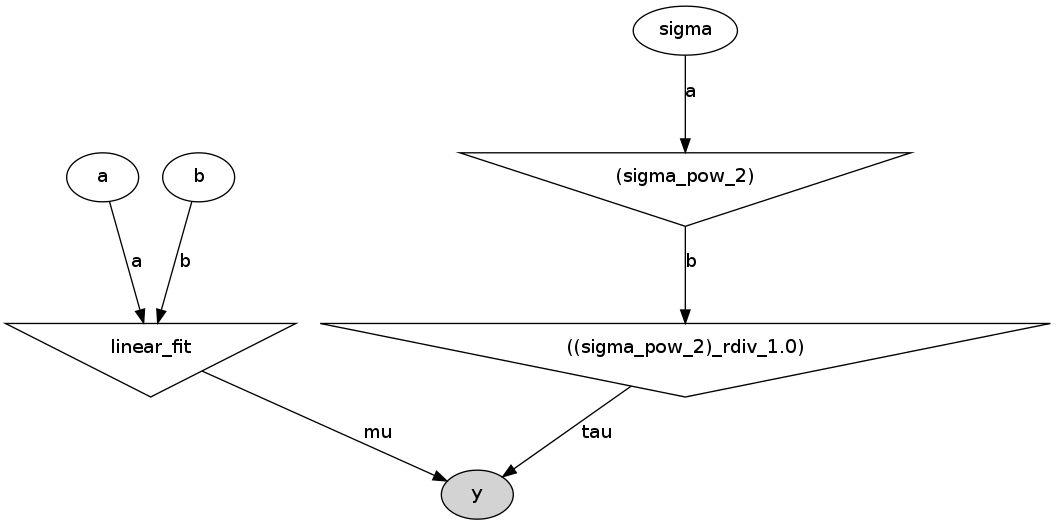
Это прямой ацикличный граф, представляющий нашу модель. Белые эллипсы показывают стохастические узлы (это a, b и sigma), треугольники — детерминистические узлы, а затемненный эллипс включает наши псевдоэкспериментальные данные.
То есть мы видим, что значания a и b поступают в нашу модель (linear_fit), которая сама по себе является детерминистским узлом, а потом поступают в функцию правдоподобия y. Sigma сначала задается стохастическим узлом, но так как параметром в функции правдоподобия является не sigma, а tau = 1/sigma^2, то стохастическое значение sigma сначала возводится в квадрат (верхний треугольник справа), и потом считается tau. И уже tau поступает в функцию правдоподобия, так же как и наши сгенерированные данные.
Я думаю, что этот граф весьма полезен как для объяснения модели, так и для самостоятельной проверки логики
модели.
Байесовская фильтрация спама — метод для фильтрации спама, основанный на применении наивного байесовского классификатора, в основе которого лежит применение теоремы Байеса.
Содержание
[убрать]- 1 История
- 2 Описание
- 3 Математические основы
- 3.1 Вычисление вероятности того, что сообщение, содержащее данное слово, является спамом
- 3.2 Спамовость слова
- 3.3 Объединение индивидуальных вероятностей
- 3.4 Проблема редких слов
- 3.5 Другие эвристические усовершенствования
- 3.6 Смешанные методы
- 4 Характеристика
- 5 Примечания
- 6 Литература
§История
Первой известной программой, фильтрующей почту с использованием Байесовского классификатора, была программа iFile Джейсона Ренни, выпущенная в 1996. Программа использовала сортировку почты по папкам[1]. Первая академическая публикация по наивной байесовской фильтрации спама появилась в 1998[2]. Вскоре после этой публикации была развернута работа по созданию коммерческих фильтров спама[источник не указан 906 дней]. Однако в 2002 г. Пол Грэм смог значительно уменьшить число ложноположительных срабатываний до такой степени, что байесовский фильтр мог использоваться в качестве единственного фильтра спама[3][4][5].
Модификации основного подхода были развиты во многих исследовательских работах и внедрены в программных продуктах[6]. Многие современные почтовые клиенты осуществляют байесовское фильтрование спама. Пользователи могут также установить отдельные программы фильтрования почты. Фильтры для почтового сервера, такие как DSPAM, SpamAssassin, SpamBayes, SpamProbe, Bogofilter, CRM114 используют методы байесовского фильтрования спама[5]. Программное обеспечение серверов электронной почты либо включает фильтры в свою поставку, либо предоставляет API для подключения внешних модулей.
§Описание
При обучении фильтра для каждого встреченного в письмах слова высчитывается и сохраняется его «вес» — оценка вероятности того, что письмо с этим словом — спам. В простейшем случае в качестве оценки используется частота: «появлений в спаме / появлений всего». В более сложных случаях возможна предварительная обработка текста: приведение слов в начальную форму, удаление служебных слов, вычисление «веса» для целых фраз, транслитерация и прочее.
При проверке вновь пришедшего письма вероятность «спамовости» вычисляется по указанной выше формуле для множества гипотез. В данном случае «гипотезы» — это слова, и для каждого слова «достоверность гипотезы» 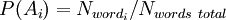 — доля этого слова в письме, а «зависимость события от гипотезы»
— доля этого слова в письме, а «зависимость события от гипотезы» 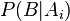 — вычисленный ранее «вес» слова. То есть «вес» письма в данном случае — усредненный «вес» всех его слов.
— вычисленный ранее «вес» слова. То есть «вес» письма в данном случае — усредненный «вес» всех его слов.
Отнесение письма к «спаму» или «не-спаму» производится по тому, превышает ли его «вес» некую планку, заданную пользователем (обычно берут 60-80 %). После принятия решения по письму в базе данных обновляются «веса» для вошедших в него слов.
§Математические основы
Почтовые байесовские фильтры основываются на теореме Байеса. Теорема Байеса используется несколько раз в контексте спама: в первый раз, чтобы вычислить вероятность, что сообщение — спам, зная, что данное слово появляется в этом сообщении; во второй раз, чтобы вычислить вероятность, что сообщение — спам, учитывая все его слова (или соответствующие их подмножества); иногда в третий раз, когда встречаются сообщения с редкими словами.
§Вычисление вероятности того, что сообщение, содержащее данное слово, является спамом
Давайте предположим, что подозреваемое сообщение содержит слово «Replica». Большинство людей, которые привыкли получать электронное письмо, знает, что это сообщение, скорее всего, будет спамом, а точнее предложением продать поддельные копии часов известных брендов. Программа обнаружения спама, однако, не «знает» такие факты, все, что она может сделать—вычислить вероятности.
Формула, используемая программным обеспечением, чтобы определить это, получена из теоремы Байеса и формулы полной вероятности:
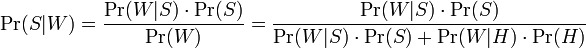
где:
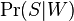 — условная вероятность того, что сообщение—спам, при условии, что слово «Replica» находится в нем;
— условная вероятность того, что сообщение—спам, при условии, что слово «Replica» находится в нем;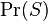 — полная вероятность того, что произвольное сообщение—спам;
— полная вероятность того, что произвольное сообщение—спам;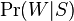 — условная вероятность того, что слово «replica» появляется в сообщениях, если они являются спамом;
— условная вероятность того, что слово «replica» появляется в сообщениях, если они являются спамом;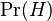 — полная вероятность того, что произвольное сообщение не спам (то есть «ham»);
— полная вероятность того, что произвольное сообщение не спам (то есть «ham»);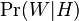 — условная вероятность того, что слово «replica» появляется в сообщениях, если они являются «ham».
— условная вероятность того, что слово «replica» появляется в сообщениях, если они являются «ham».
§Спамовость слова
Недавние статистические исследования[7] показали, что на сегодняшний день вероятность любого сообщения быть спамом составляет по меньшей мере 80 %: 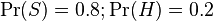 .
.
Однако большинство байесовских программ обнаружения спама делают предположение об отсутствии априорных предпочтений у сообщения быть «spam», а не «ham», и полагает, что у обоих случаев есть равные вероятности 50 %: 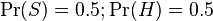 .
.
О фильтрах, которые используют эту гипотезу, говорят, как о фильтрах «без предубеждений». Это означает, что у них нет никакого предубеждения относительно входящей электронной почты. Это предположение позволяет упрощать общую формулу до:
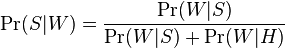
Значение 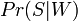 называют «спамовостью» слова
называют «спамовостью» слова 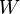 , при этом число , используемое в формуле выше, приближенно равно относительной частоте сообщений, содержащих слово в сообщениях, идентифицированных как спам во время фазы обучения, то есть:
, при этом число , используемое в формуле выше, приближенно равно относительной частоте сообщений, содержащих слово в сообщениях, идентифицированных как спам во время фазы обучения, то есть:
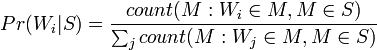
Точно так же приближенно равно относительной частоте сообщений, содержащих слово в сообщениях, идентифицированных как «ham» во время фазы обучения.
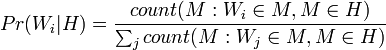
Для того, чтобы эти приближения имели смысл, набор обучающих сообщений должен быть большим и достаточно представительным. Также желательно чтобы набор обучающих сообщений соответствовал 50 % гипотезе о перераспределении между спамом и «ham», то есть что наборы сообщений «spam» и «ham» имели один и тот же размер.
Конечно, определение, является ли сообщение «spam» или «ham», базируемой только на присутствии лишь одного определённого слова, подвержено ошибкам, именно поэтому байесовские фильтры спама пытаются рассмотреть несколько слов и комбинировать их спамовость, чтобы определить полную вероятность того, что сообщение является спамом.
§Объединение индивидуальных вероятностей
Программные спам-фильтры, построенные на принципах наивного байесовского классификатора, делают «наивное» предположение о том, что события, соответствующие наличию того или иного слова в электронном письме или сообщении, являются независимыми по отношению друг к другу. Это упрощение в общем случае является неверным для естественных языков таких как английский, где вероятность обнаружения прилагательного повышается при наличии, к примеру, существительного. Исходя из такого «наивного» предположения, для решения задачи классификации сообщений лишь на 2 класса: 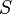 (спам) и
(спам) и 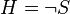 («хэм», то есть не спам) из теоремы Байеса можно вывести следующую формулу оценки вероятности «спамовости» всего сообщения, содержащего слова
(«хэм», то есть не спам) из теоремы Байеса можно вывести следующую формулу оценки вероятности «спамовости» всего сообщения, содержащего слова 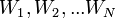 :
:
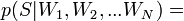 [по теореме Байеса]
[по теореме Байеса] 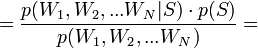 [так как
[так как 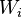 — предполагаются независимыми]
— предполагаются независимыми] 
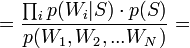 [по теореме Байеса]
[по теореме Байеса] 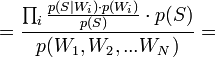 [по формуле полной вероятности]
[по формуле полной вероятности]
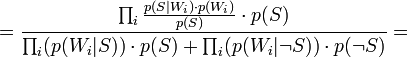
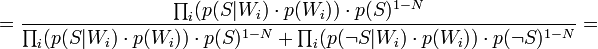
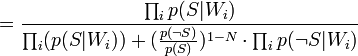
Таким образом, предполагая 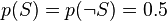 , имеем:
, имеем:
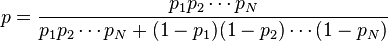
где:
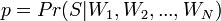 — вероятность, что сообщение, содержащее слова
— вероятность, что сообщение, содержащее слова 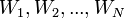 — спам;
— спам;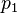 — условная вероятность
— условная вероятность 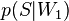 того, что сообщение — спам, при условии, что оно содержит первое слово (к примеру «replica»);
того, что сообщение — спам, при условии, что оно содержит первое слово (к примеру «replica»);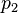 — условная вероятность
— условная вероятность 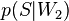 того, что сообщение — спам, при условии, что оно содержит второе слово (к примеру «watches»);
того, что сообщение — спам, при условии, что оно содержит второе слово (к примеру «watches»);- и т. д.
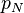 — условная вероятность
— условная вероятность 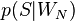 того, что сообщение — спам, при условии, что оно содержит Nое слово (к примеру «home»).
того, что сообщение — спам, при условии, что оно содержит Nое слово (к примеру «home»).
(Demonstration:[8])
Результат p обычно сравнивают с некоторым порогом, например, 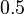 , чтобы решить, является ли сообщение спамом или нет. Если p ниже чем порог, сообщение рассматривают как вероятный «ham», иначе его рассматривают как вероятный спам.
, чтобы решить, является ли сообщение спамом или нет. Если p ниже чем порог, сообщение рассматривают как вероятный «ham», иначе его рассматривают как вероятный спам.
§Проблема редких слов
Она возникает в случае, если слово никогда не встречалось во время фазы обучения: и числитель, и знаменатель равны нулю, и в общей формуле, и в формуле спамовости.
В целом, слова, с которыми программа столкнулась только несколько раз во время фазы обучения, не являются репрезентативными (набор данных в выборке мал для того, чтобы сделать надёжный вывод о свойстве такого слова). Простое решение состоит в том, чтобы игнорировать такие ненадёжные слова.
§Другие эвристические усовершенствования
«Нейтральные» слова такие, как, «the», «a», «some», или «is» (в английском языке), или их эквиваленты на других языках, могут быть проигнорированы. Вообще говоря, некоторые байесовские фильтры просто игнорируют все слова, у которых спамовость около 0.5, так как в этом случае получается качественно лучшее решение. Учитываются только те слова, спамовость которых около 0.0 (отличительный признак законных сообщений — «ham»), или рядом с 1.0 (отличительный признаки спама). Метод отсева может быть настроен например так, чтобы держать только те десять слов в исследованном сообщении, у которых есть самое большое absolute value |0.5 ? Pr|.
Некоторые программные продукты принимают во внимание тот факт, что определённое слово появляется несколько раз в проверяемом сообщении[9], другие не делают.
Некоторые программные продукты используют словосочетания — patterns (последовательности слов) вместо изолированных слов естественных языков[10]. Например, с «контекстным окном» из четырех слов, они вычисляют спамовость словосочетания «Виагра, хорошо для», вместо того, чтобы вычислить спамовости отдельных слов «Виагры», «хорошо», и «для». Этот метод более чувствителен к контексту и устраняет байесовский шум лучше, за счет большей базы данных.
§Смешанные методы
Кроме «наивного» байесовского подхода есть и другие способы скомбинировать—объединить отдельные вероятности для различных слов. Эти методы отличаются от «наивного» метода предположениями, которые они делают о статистических свойствах входных данных. Две различные гипотезы приводят к радикально различным формулам для совокупности (объединения) отдельных вероятностей.
Например, для проверки предположения о совокупности отдельных вероятностей, логарифм произведения которых, с точностью до константы подчиняетсяраспределению хи-квадрат с 2N степенями свободы, можно было использовать формулу:
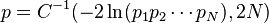
где C?1 is the inverse of the chi-square function.
Отдельные вероятности могут быть объединены также методами марковской дискриминации.
§Характеристика
Данный метод прост (алгоритмы элементарны), удобен (позволяет обходиться без «черных списков» и подобных искусственных приемов), эффективен (после обучения на достаточно большой выборке отсекает до 95—97 % спама, и в случае любых ошибок его можно дообучать). В общем, есть все показания для его повсеместного использования, что и имеет место на практике — на его основе построены практически все современные спам-фильтры.
Впрочем, у метода есть и принципиальный недостаток: он базируется на предположении, что одни слова чаще встречаются в спаме, а другие — в обычных письмах, и неэффективен, если данное предположение неверно. Впрочем, как показывает практика, такой спам даже человек не в состоянии определить «на глаз» — только прочтя письмо и поняв его смысл. Существует метод Байесова отравления (англ.), позволяющий добавить много лишнего текста, иногда тщательно подобранного, чтобы «обмануть» фильтр.
Еще один не принципиальный недостаток, связанный с реализацией — метод работает только с текстом. Зная об этом ограничении, спамеры стали вкладывать рекламную информацию в картинку. Текст же в письме либо отсутствует, либо не несёт смысла. Против этого приходится пользоваться либо средствами распознавания текста («дорогая» процедура, применяется только при крайней необходимости), либо старыми методами фильтрации — «черные списки» и регулярные выражения (так как такие письма часто имеют стереотипную форму).