Что такое «сигма»?
Что такое «сигма»?
http://elementy.ru/LHC/HEP/study/errors/sigma
Сигмой (?) в статистическом анализе обозначают стандартное отклонение. Опуская тонкости, которые будут обсуждены ниже, можно сказать, что стандартное отклонение — это та погрешность, то «± сколько-то», которым обязательно сопровождают измерение величины. Если вы измерили массу предмета и получили результат 100 ± 5 грамм, то величина «110 грамм» отличается от измеренного результата на два стандартных отклонения (то есть на 2 сигмы), величина «50 грамм» отличается на 10 стандартных отклонений (на 10 сигм).
Зачем всё это нужно: сигмы и вероятности
При обсуждении погрешностей мы уже говорили, что фраза «измеренная масса равна 100 ± 5 грамм» вовсе не означает, что истинная масса гарантированно лежит в интервале от 95 до 105 грамм. Она может оказаться и за пределами этого интервала «± 1?», но, как правило, недалеко. В небольшом проценте случаев может даже случиться, что она выходит за пределы интервала «± 2?», и уж совсем редко она оказывается за пределами «± 3?». В общем, тенденция ясна: количество сигм связано с вероятностью того, что истинное значение будет настолько отличаться от измеренного.
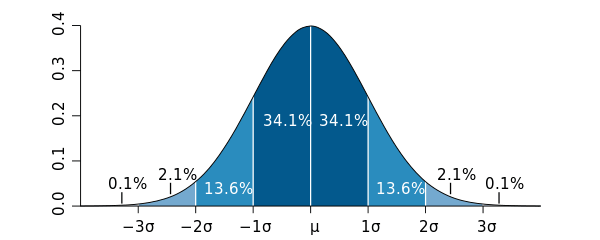
Пропустим все математические подробности и покажем результат для самого простого и распространенного случая, который называется «нормальное распределение» (см. рисунок). Вероятность попасть в интервал ± 1? — примерно 68%, в интервал ± 2? — примерно 95%, в интервал ± 3? — примерно 99,8%, и т. д. Итак, можно сформулировать некую договоренность:
Договоренность: выражение какого-то отличия в количестве сигм — это сообщение о том, какова вероятность, что такое или еще более сильное отличие могло произойти за счет случайного стечения обстоятельств при измерении.
Использовать эту договоренность можно разными способами. Если вы просто сообщаете результат измерения (100 ± 5 грамм) и уверены в том, что нормальное распределение применимо, то вы можете сказать, что истинное значение массы с вероятностью 68% лежит в этом интервале, с вероятностью 95% лежит в интервале от 90 до 110 грамм, и т. д.
Вы можете также сравнивать результат вашего измерения с чужим измерением той же самой величины или с теоретическими расчетами. Вы видите, что числа отличаются, и хотите понять, имеете ли вы право утверждать, что между двумя результатами есть статистически значимое расхождение — то есть несогласие, которое нельзя списать на случайную статистическую флуктуацию в данных. Тогда утверждения звучат так:
- Если отличие составляет меньше 1?, то вероятность того, что два числа согласуются друг с другом, больше 32%. В таком случае просто говорят, что два результата совпадают в пределах погрешностей.
- Если отличие составляет меньше 3?, то вероятность того, что два числа согласуются друг с другом, больше 0,2%. В физике элементарных частиц такой вероятности недостаточно для каких-либо серьезных выводов, и принято говорить: различие между двумя результатами не является статистически значимым.
- Если отличие от 3? до 5?, то это повод подозревать что-то серьезное. Впрочем, даже в этом случае физики говорят осторожно: данные указывают на существование различия между двумя результатами.
- И только если два результата отличаются на 5? или больше, физики четко заявляют: два результата отличаются друг от друга.
Эти выражения особенно стандартны, когда речь идет о поиске новой частицы. Вы сравниваете экспериментальные данные с теоретическим предсказанием, сделанным без новой частицы, и, если видите отличие от 3 до 5 сигм, вы говорите: получено указание на существование новой частицы (по-английски, evidence). Если же отличие превышает 5 сигм, вы говорите: мы открыли новую частицу (discovery).
Пример 1
Предположим, что вы изучаете какой-то редкий распад мезона и сравниваете его с теоретическим предсказанием в рамках Стандартной модели. Для удобства записи вы выразили результат измерения в виде такой величины:
? = (измеренная вероятность распада) / (теоретически предсказанная вероятность распада)
и получили ответ: ? = 1,25 ± 0,25. Что вы можете сказать про этот результат?
Во-первых, он отличается от нуля на пять сигм. Значит, он уже классифицируется как открытие, и поэтому вы можете смело заявлять: мы открыли искомый распад мезона (если, конечно, это уже не сделал кто-то до вас; тогда вам придется довольствоваться скромным «подтверждением открытия»). Во-вторых, он отличается от единицы на одну сигму. Такое отклонение «неинтересно», оно не позволяет вам сказать, что вы обнаружили какое-то статистически значимое отличие от теоретических расчетов. Поэтому вы добавляете: измеренное значение согласуется с предсказаниями Стандартной модели.
Предположим далее, что вы набрали в 25 раз больше статистики, перемеряли эту вероятность и получили уточненное значение: ? = 1,20 ± 0,05. Отличие от нуля составляет уже 24 сигмы, так что сомнений в реальности эффекта больше не остается. Отличие от единицы составляет теперь 4 сигмы. Этого еще недостаточно для того, чтобы заявить, что вы открыли Новую физику. Но вы можете четко сказать, что ваши данные расходятся с теоретическими предсказаниями на уровне 4 сигм и указывают на существование эффекта вне Стандартной модели.
Пример 2
Вы изучаете рождение мюонов и антимюонов в каком-то процессе и хотите узнать, можно ли сделать вывод о том, что они рождаются с разной вероятностью. Для мюонов (?–) вы получили вероятность рождения x– = 0,18 ± 0,03, а для антимюонов (?+) – x+ = 0,30 ± 0,04. Разница получается 0,12, но насколько значимым является это различие?
Если для обеих погрешностей справедливы нормальные распределения, а также если эти погрешности полностью независимы (между ними нет корреляций), то общая погрешность величины x+ – x– вычисляется по формуле суммирования квадратов. Поэтому результат измерения x+ – x– = 0,12 ± 0,05. Отличие составляет 2,4 сигмы, и этого еще недостаточно для каких-либо серьезных выводов.
«Уверенность» против «статистической значимости»
Заметьте, что в приведенных выше примерах нас интересовали вопросы, на которые можно ответить «да» или «нет». Проступает ли в полученных данных какая-то новая частица? Согласуется ли распределение по импульсу с теоретическими расчетами? Зависит ли сечение процесса от энергии столкновений? Совпадает ли масса у частицы и ее античастицы? Попытка ответить на эти вопросы с помощью данных называется на научном языке проверкой гипотез. Вопросы, которые требуют развернутого ответа (подсчитать что-то, объяснить что-то и т. п.), гипотезами не называются.
В простейшем приближении результат экспериментальной проверки гипотезы выглядит так: ответ «да» с вероятностью p и ответ «нет» с вероятностью 1 – p. Эти вероятности очень важны для сообщения результата; физики обычно избегают абсолютных утверждений («мы открыли» или «мы опровергли») без указания вероятностей.
Но тут сразу же надо сделать важное уточнение. Если его четко осознать, то станет понятным, почему такие стандартные для научно-популярных новостей фразы, как «Ученые на 99% уверены, что открыли что-то новое», — обманчивы.
Точная формулировка, которую обычно используют ученые, такова:
При проверке гипотезы получен ответ «да» на уровне статистической значимости p.
При этом величина p часто выражается в виде количества сигм. В англоязычной литературе используется словосочетание confidence level, CL (доверительный уровень). В русскоязычной еще иногда говорят «статистическая достоверность», но такое выражение может привести к путанице в понимании.
Отличие «популярной» фразы от истинного утверждения вот в чём. Во всяком измерении есть не только статистические, но и систематические погрешности. Описанные выше правила связи вероятностей и количества сигм работают только для статистических погрешностей — и то если к ним применимо нормальное распределение. Если статистические погрешности всегда можно обсчитать аккуратно, то систематические погрешности — это немножко искусство. Более того, из многолетнего опыта известно, что сильные систематические отклонения уж точно не описываются нормальным распределением, и потому для них эти правила пересчета не справедливы. Так что даже если экспериментаторы всё перепроверили много раз и указали систематическую погрешность, всегда остается риск, что они что-то упустили из виду. Корректно оценить этот риск невозможно, поэтому вы на самом деле не знаете, с какой истинной вероятностью ваш ответ верен.
Конечно, по умолчанию систематическим погрешностям стоит доверять, особенно если они исходят от опытных экспериментальных групп. Но вековой опыт изучения элементарных частиц показывает, что несмотря на все предосторожности регулярно случаются проколы. Бывает, что коллаборация получает результат, сильно противоречащий какой-то гипотезе, перепроверяет анализ много раз и никаких ошибок у себя не находит. Однако этот результат затем не подтверждается другими — порой намного более точными! — экспериментами. Почему первый эксперимент дал такой странный результат, что в нём было не то, где там ошибка или неучтенная погрешность — всё это зачастую так и остается непонятым (впрочем, иногда источник ошибки быстро вскрывается, как это случилось со «сверхсветовыми» нейтрино в эксперименте OPERA).
Физики к таким оборотам событий уже привыкли, поэтому каждый экспериментальный результат, сильно отличающийся от всей сложившейся к тому времени картины, вызывает оправданный скепсис. Физики так консервативны в своем отношении вовсе не потому, что они ретрограды и намертво уверовали в какую-то одну теорию, как это хотят представить опровергатели физики. Они просто научены всем предыдущим опытом в физике частиц и знают, чем это обычно кончается. Поэтому без независимого подтверждения другими экспериментами подобные сенсации они не поддерживают.
ФЭЧ в сравнении с другими науками
Надо сказать, что сформулированные выше жесткие критерии статистической достоверности характерны именно для физики элементарных частиц и некоторых смежных разделов. Во многих других разделах физики, а тем более в других дисциплинах (в особенности, в биомедицинских науках) критерии намного слабее.
Предположим, вы измерили некие данные и хотите узнать, какова вероятность того, что они «вписываются в норму». Вы проводите статистический тест, который дает вам вероятность того, что «нормальная ситуация» без какого-либо реального отклонения только за счет статистической флуктуации даст вот такое или еще более сильное отклонение. Эта вероятность называется p-значение. В биологии пороговое p-значение, ниже которого уже уверенно говорят про реальное отличие, составляет один или даже несколько процентов. В физике элементарных частиц такое отличие вообще не считают значимым, тут нет даже «указания на существование» какого-то отличия! Ответственное заявление об отличии звучит в ФЭЧ только для p-значений меньше одной двухмиллионной (то есть отклонение больше 5?). Такой жесткий подход к достоверности утверждений выработался в ФЭЧ примерно полвека назад, в эпоху, когда экспериментаторы видели много отклонений со значимостью в районе 3? и смело заявляли об открытии новых частиц, хотя потом эти «открытия» не подтверждались. Подробный рассказ об истоках этого критерия см. в постах Tommaso Dorigo (часть 1, часть 2).
Вероятность того, что истинное значение попадет в определенный интервал около измеренного среднего значения при нормальном распределении ошибок. Изображение с сайта en.wikipedia.org