Что такое нейронная сеть и многослойный персептрон
Что такое нейронная сеть и многослойный персептрон?
Под нейронной сетью обычно понимают
специальную математическую модель и ее программную и/или аппаратную реализацию.
Существуют нейронные сети различной архитектуры. В данной работе представлена Multi-Layer
Feed Forward Neural Network (многослойная сеть прямого распространения) или Multi-Layer
Perceptron (MLP), как наиболее часто использующаяся на практике для решения
задач классификации и аппроксимации. 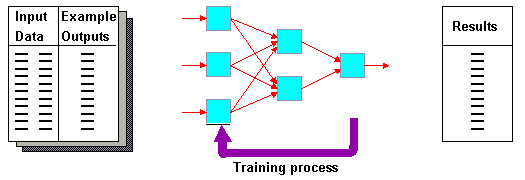
MLP работает в двух режимах – режиме обучения и режиме тестирования (работы обученной модели). Допустим среднесуточная температура воздуха зависит от широты, долготы и даты. Нам известны результаты многолетних наблюдений, т.е. входные данные и выходной результат. Наша задача подобрать такие параметры сети, которые по заданным входам дают известный выход. Режим такого подбора и называется режимом обучения.
MLP может иметь различное количество входов, выходов (обычно определяется постановкой задачи), скрытых слоев, нейронов на слое.
В процессе обучения в простейшем случае подбираются веса связей. Процесс преобразования входных величин идет по направлению связей сигнального графа. На входном слое каждая входная величина расходится по связям (по каждой исходящей из вершины входного слоя дуге идет “сигнал” равный входной величине), умножается на вес дуги и суммируется на скрытом слое, а далее преобразуется передаточной функцией нейрона.
На выходном слое обычно сигнал только суммируется.
Суть обучения заключается в решении задачи подбора параметров сети (весов связей) для минимизации функции ошибки. Причем из всех обучающих примеров часть используется только для контроля.
Ряд полезных ссылок и комментариев см. на странице авторов >
Отбор данных
На всех предыдущих этапах существенно использовалось одно предположение. А именно, обучающая, контрольная и тестовая выборки должны быть репрезентативными (представительными) с точки зрения существа задачи (более того, эти выборки должны быть репрезентативными каждая в отдельности). Известное изречение программистов "garbage in, garbage out" ("мусор на входе - мусор на выходе") нигде не справедливо в такой степени, как при нейросетевом моделировании. Если обучающие данные не репрезентативны, то модель, как минимум, будет не очень хорошей, а в худшем случае - бесполезной. Имеет смысл перечислить ряд причин, которые ухудшают качество обучающей выборки:
Будущее не похоже на прошлое. Обычно в качестве обучающих берутся исторические данные. Если обстоятельства изменились, то закономерности, имевшие место в прошлом, могут больше не действовать.
Следует учесть все возможности. Нейронная сеть может обучаться только на тех данных, которыми она располагает. Предположим, что лица с годовым доходом более $100,000 имеют высокий кредитный риск, а обучающая выборка не содержала лиц с доходом более $40,000 в год. Тогда едва ли можно ожидать от сети правильного решения в совершенно новой для нее ситуации.
Сеть обучается тому, чему проще всего обучиться. Классическим (возможно, вымышленным) примером является система машинного зрения, предназначенная для автоматического распознавания танков. Сеть обучалась на ста картинках, содержащих изображения танков, и на ста других картинках, где танков не было. Был достигнут стопроцентно правильный результат. Но когда на вход сети были поданы новые данные, она безнадежно провалилась. В чем же была причина? Выяснилось, что фотографии с танками были сделаны в пасмурный, дождливый день, а фотографии без танков - в солнечный день. Сеть научилась улавливать (очевидную) разницу в общей освещенности. Чтобы сеть могла результативно работать, ее следовало обучать на данных, где бы присутствовали все погодные условия и типы освещения, при которых сеть предполагается использовать - и это еще не говоря о рельефе местности, угле и дистанции съемки и т.д.
Несбалансированный набор данных. Коль скоро сеть минимизирует общую погрешность, важное значение приобретают пропорции, в которых представлены данные различных типов. Сеть, обученная на 900 хороших и 100 плохих примерах будет искажать результат в пользу хороших наблюдений, поскольку это позволит алгоритму уменьшить общую погрешность (которая определяется в основном хорошими случаями). Если в реальной популяции хорошие и плохие объекты представлены в другой пропорции, то результаты, выдаваемые сетью, могут оказаться неверными. Хорошим примером служит задача выявления заболеваний. Пусть, например, при обычных обследованиях в среднем 90% людей оказываются здоровыми. Сеть обучается на имеющихся данных, в которых пропорция здоровые/больные равна 90/10. Затем она применяется для диагностики пациентов с определенным жалобами, среди которых это соотношение уже 50/50. В этом случае сеть будет ставить диагноз чересчур осторожно и не распознает заболевание у некоторых больных. Если же, наоборот, сеть обучить на данных "с жалобами", а затем протестировать на "обычных" данных, то она будет выдавать повышенное число неправильных диагнозов о наличии заболевания. В таких ситуациях обучающие данные нужно скорректировать так, чтобы были учтены различия в распределении данных (например, можно повторять редкие наблюдения или удалить часто встречающиеся), или же видоизменить решения, выдаваемые сетью, посредством матрицы потерь (Bishop, 1995). Как правило, лучше всего постараться сделать так, чтобы наблюдения различных типов были представлены равномерно, и соответственно этому интерпретировать результаты, которые выдает сеть.
Как обучается многослойный персептрон
Мы сможем лучше понять, как устроен и как обучается многослойный персептрон (МП), если выясним, какие функции он способен моделировать. Вспомним, что уровнем активации элемента называется взвешенная сумма его входов с добавленным к ней пороговым значением. Таким образом, уровень активации представляет собой простую линейную функцию входов. Эта активация затем преобразуется с помощью сигмоидной (имеющей S-образную форму) кривой. Комбинация линейной функции нескольких переменных и скалярной сигмоидной функции приводит к характерному профилю "сигмоидного склона", который выдает элемент первого промежуточного слоя МП (На приведенном здесь рисунке соответствующая поверхность изображена в виде функции двух входных переменных. Элемент с большим числом входов выдает многомерный аналог такой поверхности). При изменении весов и порогов меняется и поверхность отклика. При этом может меняться как ориентация всей поверхности, так и крутизна склона. Большим значениям весов соответствует более крутой склон. Так например, если увеличить все веса в два раза, то ориентация не изменится, а наклон будет более крутым.
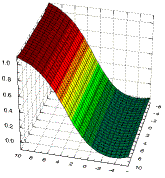
Рисунок 1. Сигмоидальный склон
В многослойной сети подобные функции отклика комбинируются друг с другом с помощью последовательного взятия их линейных комбинаций и применения нелинейных функций активации. На следующем рисунке изображена типичная поверхность отклика для сети с одним промежуточным слоем, состоящим из двух элементов, и одним выходным элементом, для классической задачи "исключающего или" (Xor). Две разных сигмоидных поверхности объединены в одну поверхность, имеющую форму буквы "U".
Перед началом обучения сети весам и порогам случайным образом присваиваются небольшие по величине начальные значения. Тем самым отклики отдельных элементов сети имеют малый наклон и ориентированы хаотично - фактически они не связаны друг с другом. По мере того, как происходит обучение, поверхности отклика элементов сети вращаются и сдвигаются в нужное положение, а значения весов увеличиваются, поскольку они должны моделировать отдельные участки целевой поверхности отклика.
В задачах классификации выходной элемент должен выдавать сильный сигнал в случае, если данное наблюдение принадлежит к интересующему нас классу, и слабый - в противоположном случае. Иначе говоря, этот элемент должен стремиться смоделировать функцию, равную единице в той области пространства объектов, где располагаются объекты из нужного класса, и равную нулю вне этой области.
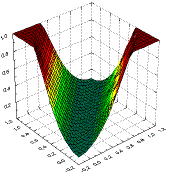
Рисунок 2. Поверхность отклика в задаче исключающего ИЛИ
Такая конструкция известна как дискриминантная функция в задачах распознавания. "Идеальная" дискриминантная функция должна иметь плоскую структуру, так чтобы точки соответствующей поверхности располагались либо на нулевом уровне, либо на высоте единица.
Если сеть не содержит скрытых элементов, то на выходе она может моделировать только одинарный "сигмоидный склон": точки, находящиеся по одну его сторону, располагаются низко, по другую - высоко. При этом всегда будет существовать область между ними (на склоне), где высота принимает промежуточные значения, но по мере увеличения весов эта область будет сужаться.
Такой сигмоидный склон фактически работает как линейная дискриминантная функция. Точки, лежащие по одну сторону склона, классифицируются как принадлежащие нужному классу, а лежащие по другую сторону - как не принадлежащие. Следовательно, сеть без скрытых слоев может служить классификатором только в линейно-отделимых задачах (когда можно провести линию - или, в случае более высоких размерностей, - гиперплоскость, разделяющую точки в пространстве признаков).
Сеть, содержащая один промежуточный слой, строит несколько сигмоидных склонов - по одному для каждого скрытого элемента, - и затем выходной элемент комбинирует из них "возвышенность". Эта возвышенность получается выпуклой, т.е. не содержащей впадин. При этом в некоторых направлениях она может уходить на бесконечность (как длинный полуостров). Такая сеть может моделировать большинство реальных задач классификации. На рисунке ниже показана поверхность отклика, полученная многослойным персептроном для решения задачи исключающего или: хорошо видно, что она выделяет область пространства, расположенную вдоль диагонали.
Сеть с двумя промежуточными слоями строит комбинацию из нескольких таких возвышенностей. Их будет столько же, сколько элементов во втором слое, и у каждой из них будет столько сторон, сколько элементов было в первом скрытом слое. После небольшого размышления можно прийти к выводу, что, используя достаточное число таких возвышенностей, можно воспроизвести поверхность любой формы - в том числе с впадинами и вогнутостями.
Как следствие наших рассмотрений мы получаем, что, теоретически, для моделирования любой задачи достаточно многослойного персептрона с двумя промежуточными слоями (в точной формулировке этот результат известен как теорема Колмогорова). При этом может оказаться и так, что для решения некоторой конкретной задачи более простой и удобной будет сеть с еще большим числом слоев. Однако, для решения большинства практических задач достаточно всего одного промежуточного слоя, два слоя применяются как резерв в особых случаях, а сети с тремя слоями практически не применяются.
В задачах классификации очень важно понять, как следует интерпретировать те точки, которые попали на склон или лежат близко от него. Стандартный выход здесь состоит в том, чтобы для пороговых значений установить некоторые доверительные пределы (принятия или отвержения), которые должны быть достигнуты, чтобы данных элемент считался "принявшим решение". Например, если установлены пороги принятия/отвержения 0.95/0.05, то при уровне выходного сигнала, превосходящем 0.95 элемент считается активным, при уровне ниже 0.05 - неактивным, а в промежутке - "неопределенным".
Имеется и более тонкий (и, вероятно, более полезный) способ интерпретировать уровни выходного сигнала: считать их вероятностями. В этом случае сеть выдает несколько большую информацию, чем просто "да/нет": она сообщает нам, насколько (в некотором формальном смысле) мы можем доверять ее решению. Разработаны (и реализованы в пакете STATISTICA Нейронные Сети ) модификации метода МП, позволяющие интерпретировать выходной сигнал нейронной сети как вероятность, в результате чего сеть по существу учится моделировать плотность вероятности распределения данного класса. При этом, однако, вероятностная интерпретация обоснована только в том случае, если выполнены определенные предположения относительно распределения исходных данных (конкретно, что они являются выборкой из некоторого распределения, принадлежащего к семейству экспоненциальных распределений; Bishop, 1995). Здесь, как и ранее, может быть принято решение по классификации, но, кроме того, вероятностная интерпретация позволяет ввести концепцию "решения с минимальными затратами".
Другие алгоритмы обучения МП
Выше было описано, как с помощью алгоритма обратного распространения осуществляется градиентный спуск по поверхности ошибок. Вкратце дело происходит так: в данной точке поверхности находится направление скорейшего спуска, затем делается прыжок вниз на расстояние, пропорциональное коэффициенту скорости обучения и крутизне склона, при этом учитывается инерция, те есть стремление сохранить прежнее направление движения. Можно сказать, что метод ведет себя как слепой кенгуру - каждый раз прыгает в направлении, которое кажется ему наилучшим. На самом деле шаг спуска вычисляется отдельно для всех обучающих наблюдений, взятых в случайном порядке, но в результате получается достаточно хорошая аппроксимация спуска по совокупной поверхности ошибок. Существуют и другие алгоритмы обучения МП, однако все они используют ту или иную стратегию скорейшего продвижения к точке минимума.
В некоторых задачах бывает целесообразно использовать такие - более сложные - методы нелинейной оптимизации. В пакете STATISTICA Нейронные Сети реализованы два подобных метода: и (Bishop, 1995; Shepherd, 1997), представляющие собой очень удачные варианты реализации двух типов алгоритмов: линейного поиска и доверительных областей.
Алгоритм линейного поиска действует следующим образом: выбирается какое-либо разумное направление движения по многомерной поверхности. В этом направлении проводится линия, и на ней ищется точка минимума (это делается относительно просто с помощью того или иного варианта метода деления отрезка пополам); затем все повторяется сначала. Что в данном случае следует считать "разумным направлением"? Очевидным ответом является направление скорейшего спуска (именно так действует алгоритм обратного распространения). На самом деле этот вроде бы очевидный выбор не слишком удачен. После того, как был найден минимум по некоторой прямой, следующая линия, выбранная для кратчайшего спуска, может "испортить" результаты минимизации по предыдущему направлению (даже на такой простой поверхности, как параболоид, может потребоваться очень большое число шагов линейного поиска). Более разумно было бы выбирать "не мешающие друг другу" направления спуска - так мы приходим к методу сопряженных градиентов (Bishop, 1995).
Идея метода состоит в следующем: поскольку мы нашли точку минимума вдоль некоторой прямой, производная по этому направлению равна нулю. Сопряженное направление выбирается таким образом, чтобы эта производная и дальше оставалась нулевой - в предположении, что поверхность имеет форму параболоида (или, грубо говоря, является "хорошей и гладкой"). Если это условие выполнено, то для достижения точки минимума достаточно будет N эпох. На реальных, сложно устроенных поверхностях по мере хода алгоритма условие сопряженности портится, и тем не менее такой алгоритм, как правило, требует гораздо меньшего числа шагов, чем метод обратного распространения, и дает лучшую точку минимума (для того, чтобы алгоритм обратного распространения точно установился в некоторой точке, нужно выбирать очень маленькую скорость обучения).
Метод доверительных областей основан на следующей идее: вместо того, чтобы двигаться в определенном направлении поиска, предположим, что поверхность имеет достаточно простую форму, так что точку минимума можно найти (и прыгнуть туда) непосредственно. Попробуем смоделировать это и посмотреть, насколько хорошей окажется полученная точка. Вид модели предполагает, что поверхность имеет хорошую и гладкую форму (например, является параболоидом), - такое предположение выполнено вблизи точек минимума. Вдали от них данное предположение может сильно нарушаться, так что модель будет выбирать для очередного продвижения совершенно не те точки. Правильно работать такая модель будет только в некоторой окрестности данной точки, причем размеры этой окрестности заранее неизвестны. Поэтому выберем в качестве следующей точки для продвижения нечто промежуточное между точкой, которую предлагает наша модель, и точкой, которая получилась бы по обычному методу градиентного спуска. Если эта новая точка оказалась хорошей, передвинемся в нее и усилим роль нашей модели в выборе очередных точек; если же точка оказалась плохой, не будем в нее перемещаться и увеличим роль метода градиентного спуска при выборе очередной точки (а также уменьшим шаг). В основанном на этой идее методе Левенберга-Маркара предполагается, что исходное отображение является локально линейным (и тогда поверхность ошибок будет параболоидом).
Метод Левенберга-Маркара (Levenberg, 1944; Marquardt, 1963; Bishop, 1995) - самый быстрый алгоритм обучения из всех, которые реализованы в пакете STATISTICA Нейронные Сети, но, к сожалению, на его использование имеется ряд важных ограничений. Он применим только для сетей с одним выходным элементом, работает только с функцией ошибок сумма квадратов и требует памяти порядка W 2 (где W - количество весов у сети; поэтому для больших сетей он плохо применим). Метод сопряженных градиентов почти так же эффективен, как и этот метод, и не связан подобными ограничениями.
При всем сказанном метод обратного распространения также сохраняет свое значение, причем не только для тех случаев, когда требуется быстро найти решение (и не требуется особой точности). Его следует предпочесть, когда объем данных очень велик, и среди данных есть избыточные. Благодаря тому, что в методе обратного распространения корректировка ошибки происходит по отдельным случаям, избыточность данных не вредит (если, например, приписать к имеющемуся набору данных еще один точно такой же набор, так что каждый случай будет повторяться дважды, то эпоха будет занимать вдвое больше времени, чем раньше, однако результат ее будет точно таким же, как от двух старых, так что ничего плохого не произойдет). Методы же Левенберга-Маркара и сопряженных градиентов проводят вычисления на всем наборе данных, поэтому при увеличении числа наблюдений продолжительность одной эпохи сильно растет, но при этом совсем не обязательно улучшается результат, достигнутый на этой эпохе (в частности, если данные избыточны; если же данные редкие, то добавление новых данных улучшит обучение на каждой эпохе). Кроме того, обратное распространение не уступает другим методам в ситуациях, когда данных мало, поскольку в этом случае недостаточно данных для принятия очень точного решения (более тонкий алгоритм может дать меньшую ошибку обучения, но контрольная ошибка у него, скорее всего, не будет меньше).
Кроме уже перечисленных, в пакете STATISTICA Нейронные Сети имеются две модификации метода обратного распространения - метод (Fahlman, 1988) и (Jacobs, 1988), - разработанные с целью преодолеть некоторые ограничения этого подхода. В большинстве случаев они работают не лучше, чем обратное распространение, а иногда и хуже (это зависит от задачи). Кроме того, в этих методах используется больше управляющих параметров, чем в других методах, и поэтому ими сложнее пользоваться.