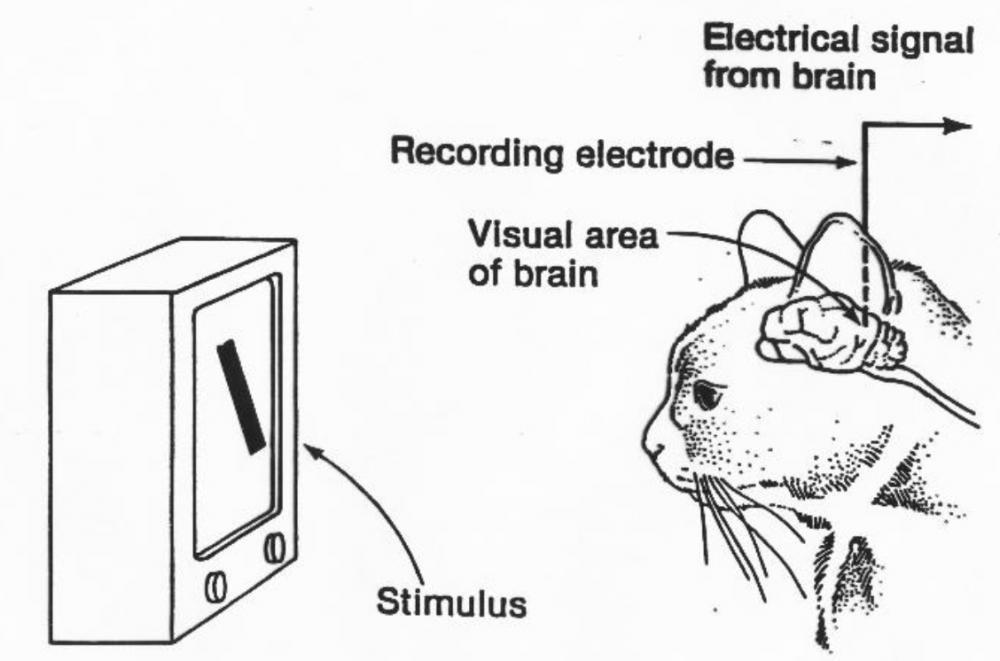
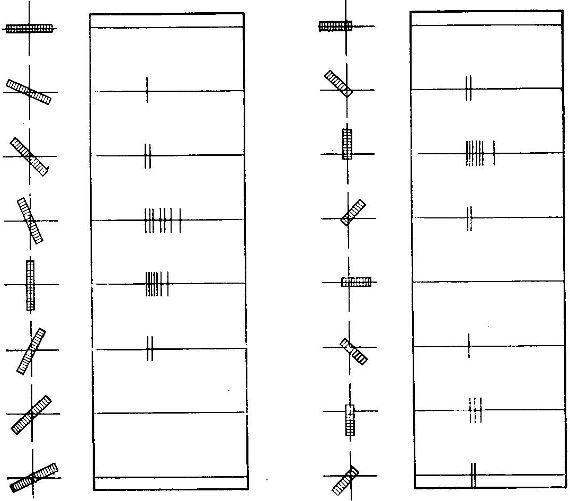
Айк - админ - админ Сообщений: 3768 |
Один из ведущих спецов Yandex про будущее ИИ: |
Род:  nan - админ Сообщений: 12306  |
Человек, который признается, что не понимает, что такое интеллект, в принципе не может быть специалистом по интеллекту, даже искусственному. У него нет этического права говорить авторитарно об этом. Он – специалист по “нейронным сетям”, которые тоже так не должны называться, как и интеллектом. Точнее он – специалист по технологии многослойных персептронов. А это не имеет никакого отношения к нейронам потому, что в мозге нет никаких многослойных персептронов:
Многослойный персептрон в принципе не может реализовать нечто большее, чем просто распознаватель, пусть и сверхточный, но даже не контекстный потому, что 1) для этого нужно последовательное развитие примитивов восприятия и действия 2) должна быть задействована личная значимость воспринимаемого и действий. А технология многослойных персептронов – это обучение сразу готовой сложной сети. Разговори дяденьки вели только о технологии многослойных персептронов и фантазировали о ее будущем развитии. |
|
Айк - админ Сообщений: 3768 |
Я, к сожалению, не настолько знаком с искусственными нейронными сетями, чтобы уверенно рассуждать о них, но практически по всем пунктам у меня вроде бы есть контрпримеры в машинном обучении:
>>> Состоит из однослойных персептронов, каждый из которых формирует свою собственную функцию распознавания Реализовано.
>>> Формируется строго поочередно (сначала созревает очередной слой и начинает специализироваться) Реализовано.
>>> Влияние соседних персептронов для контрастирования общего. Реализовано.
>>> Обучается без учителя Реализовано.
>>> Критерием верности распознавания образов восприятия-значимости-действия является сигналы специализированных рецепторов состояния гомеостаза. В какой-то мере реализовано.
В одной из недавних книг, которые я читал, Рей Курцвейл описывал свои взгляды на работу мозга и описал систему распознания речи и образов, которую он разрабатывал в течении своей жизни - она основана на иерархических скрытых марковских цепях, но это не принципиально:
Цитаты из книги Рэй Курцвейл "Эволюция разума":
1) Обучение не более одному уровню абстракции за раз:
Очень важный этап – обучение мозга, как биологического, так и компьютерного. Как я уже писал, иерархическая система распознавания образов (и цифровая, и биологическая) за один момент осваивает не больше двух иерархических уровней (а скорее один). Чтобы усовершенствовать систему, я начну с предварительно обученных иерархических сетей, которые уже научились распознавать человеческую речь, печатные буквы и структуры разговорного языка. Такая система сможет читать документы, написанные разговорным языком, но за один раз по-прежнему сможет осваивать примерно один понятийный уровень.
2) Иерархия распознавателей, латеральное торможение:
Созданная нами технология строилась практически по тем же принципам, что реализуются при мысленном распознавании образов. Она также была основана на иерархии образов, при которой каждый более высокий уровень отличался от нижестоящего уровня большей абстрактностью. Например, в системе распознавания речи основные образы звуковой частоты формировали нижние уровни, за ними следовали фонемы, затем слова и фразы (часто распознававшиеся так, как будто были словами). Некоторые системы распознавания речи могут понимать речевые команды и в таком случае включают в себя еще более высокие иерархические уровни, содержащие такие структуры, как именные и глагольные группы. Каждый распознающий модуль умеет распознавать линейную последовательность образов с нижестоящего понятийного уровня. Каждый входной сигнал характеризуется значимостью, величиной и вариабельностью величины. Существуют также и нисходящие сигналы, указывающие на ожидание образа низшего уровня.
3) Предопределенное обучение без учителя. Эволюция:
Еще один важный аспект разработки программы заключается в том, чтобы найти способ установить все те многочисленные параметры, которые контролируют функционирование системы распознавания. Среди этих параметров – допустимое число векторов для этапа векторного квантования, исходная топология иерархических состояний (до того, как в процессе тренировки ИСММ ликвидирует неиспользуемые состояния), порог распознавания на каждом иерархическом уровне, параметры, определяющие величину сигналов, и многое другое. Мы можем использовать интуитивный подход, но результаты будут далеки от оптимальных. [...] В системах распознавания речи сочетание генетических алгоритмов и скрытых моделей Маркова дало возможность получить отличные результаты. Симуляция эволюции с помощью ГА в значительной степени улучшила производительность сетей ИСММ. Эволюция позволила достичь результата, который намного превзошел исходный вариант, основанный на нашей интуиции.
4) Минимизация числа связей:
В наших системах, созданных в 1980-х и 1990-х гг., происходило автоматическое удаление контактов, вес которых был ниже определенного уровня, а также формирование новых контактов для лучшего соответствия тренировочным данным и обучения. Для оптимальной организации связей с новыми распознающими модулями мы можем использовать линейное программирование.
Это описание системы, которая лежит в основе SIRI (iPhone) и ей подобных. В ней реализовано многое из того, что, с твоих слов, якобы не реализовано в современных искусственных нейронных сетях. Да, конкретно эта система построена на иерархических скрытых марковских цепях, но принципиальных ограничений сделать тоже самое через искусственные нейронные сети, по-моему, нет.
Поэтому я не понимаю, о чём идёт речь, когда ты приводишь в пример эту таблицу сопоставлений. Ты хочешь показать неадекватность решения в лоб? Что нельзя просто взять многослойную нейронную сеть и надеяться на чудо?
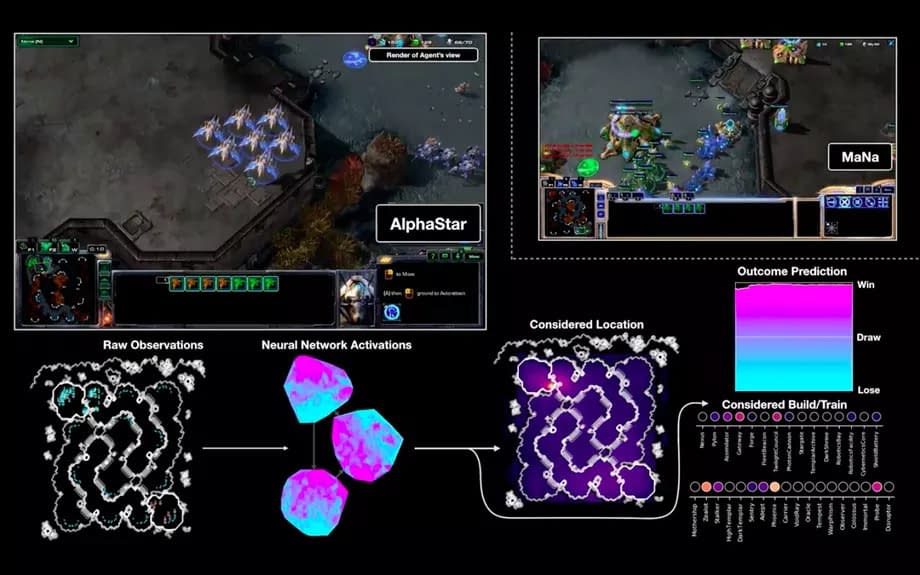
Просто, в целом, в машинном обучении, вроде бы исправлены те недостатки, на которые ты указал. Говорить о том, что не используется параметр гомеостаза, вроде бы, тоже нельзя, это достаточно очевидная идея, я думаю в AlphaStar (ИИ, который играет в Старкрафт) есть что-то подобное.
Этот набор нейронных сетей помимо всего прочего пытается предсказать исход игры (выигрываю/нечья/проигрываю) и максимизировать своё состояние "кажется выигрываю", и это вполне можно считать гомеостазом. Для этой совокупности нейросетей рай - состояние "выигрываю" и ад - состояние "проигрываю". |
|
Айк - админ Сообщений: 3768 |
На всякий случай оговорюсь, я не утверждаю, что у текущих искусственных нейронных сетей и теории машинного обучения нет проблем. Речь скорее о том, что, на мой взгляд, ты указал в таблице на те проблемы, которые в той или иной мере уже разрешены в машинном обучении. |
|
Род: kak - модератор темы Сообщений: 775 Телефон: +79217162023 |
Только не большое уточнение. Многослойный персептрон как и любая искусственная "нейронная сеть" не распознает, а классифицирует входные данные, так как для того что бы что-то распознать (узнать, знать и т.д.) необходимо: "1) для этого нужно последовательное развитие примитивов восприятия и действия 2) должна быть задействована личная значимость воспринимаемого и действий." (nan) |
|
Род: nan - админ Сообщений: 12306 |
Айк, современные нейронные сети, которые сделали прорыв в эффективности и мощный хайп это – “глубокие сети” – именно многослойный персептрон, который создается сразу и обучается как единое целое так, что никто не может сказать, какую именно функциональность берет на себя тот или иной элемент внутренних слоев. В нейронной сети распознавательная функция каждого элемента четко определена и стоит его возбудить, как в восприятии появляется соответствующий образ. Спец от Яндекса говорил именно об этих сетях. То, что кто-то где-то пробует и однослойные персептроны – вопрос другой (и там очень много проблем в реализации все по тем же причинам: личная значимость, организующая контекст).
>>Говорить о том, что не используется параметр гомеостаза, вроде бы, тоже нельзя, это достаточно очевидная идея, я думаю в AlphaStar (ИИ, который играет в Старкрафт) есть что-то подобное. Нет ничего подобного потому, что значимость задается искусственно как один из параметров, задающихся оператором, как цель распознавания. В общем-то о полном отсутствии корреляции в принципах говорят сами спецы этих сетей. |
|
Айк - админ Сообщений: 3768 |
>>> технология многослойных персептронов – это обучение сразу готовой сложной сети.
Ограниченные машины Больцмана были описаны ещё в 80-х годах.
|
|
Род: nan - админ Сообщений: 12306 |
>>Nan, откуда эти утверждения берутся? Ты сам тут же и раскрыл тему. Нет обучения отдельных однослойных персептронов, а сразу делается попытка обучения больших участков сети или всей сети. Сам термин “глубокая нейросеть” означает структуру многослойного персептрона, в которой невозможно выделить функции отдельных нейронов. Вот когда придут к пониманию, что обучать сеть нужно строго послойно, а в каждом слое формировать распознаватели профиля данного уровня, вот тогда это встанет на верный путь. Почему именно это верный очень подробно изложено и обосновано в лекциях. |
|
Айк - админ Сообщений: 3768 |
>>> сразу делается попытка обучения больших участков сети или всей сети
Пока не понимаю. Я же цитату специально привожу: можно эффективно предобучать многослойную нейронную сеть, если обучать каждый слой отдельно при помощи ограниченной машины Больцмана
То есть сначала предобучается слой А, потом следующий за ним слой Б и так далее. Что не так?
>>> в которой невозможно выделить функции отдельных нейронов
Есть специальные методы для повышения модульности слоёв.
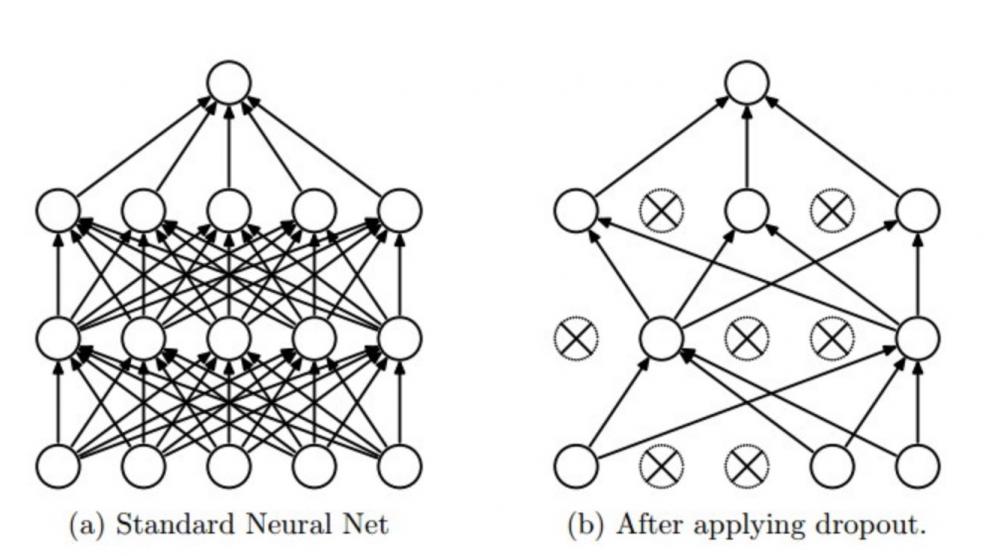
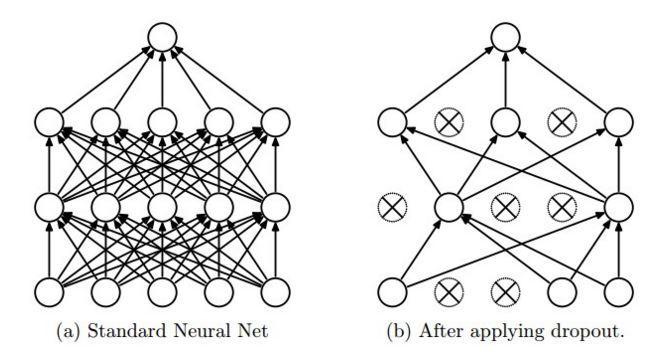
Например, широко используется "дропаут" ("метод исключения", "метод прореживания"), когда на части обучающей выборки, которая сейчас используется для обучения, часть связей все-со-всеми в выбранных слоях выпадает из вычислений. Это способствует формированию персептронов, которые распознают устойчивые, характерные признаки на данном этапе абстрагирования и не адаптируются избыточно к глобальной архитектуре сетки.
https://arxiv.org/abs/1207.0580 - Improving neural networks by preventing co-adaptation of feature detectors
Dropout предотвращает совместную адаптацию для каждого скрытого блока, делая присутствие других скрытых блоков ненадежным. Поэтому скрытый блок не может полагаться на другие блоки в исправлении собственных ошибок.
Есть эволюционное объяснение, по-моему, от Хинтона: One possible interpretation of mixability articulated in is that sex breaks up sets of co-adapted genes and this means that achieving a function by using a large set of co-adapted genes is not nearly as robust as achieving the same function, perhaps less than optimally, in multiple alternative ways, each of which only uses a small number of co-adapted genes. This allows evolution to avoid dead-ends in which improvements in fitness require co-ordinated changes to a large number of co-adapted genes. It also reduces the probability that small changes in the environment will cause large decreases in fitness a phenomenon which is known as “overfitting” in the field of machine learning.
Примерный пересказ: Все самые высокоорганизованные животные размножаются именно половым путем. Объяснение этому примерно то же, что и объяснение полезности дропаута: важно не столько собрать хорошую комбинацию генов, сколько собратъ устойчивую и хорошую комбинацию генов, которая потом будет широко воспроизводиться и сможет стать основой для новой линии потомков. А этого проще достичь, если заставлять гены, как признаки в нейронной сети, «работать» поодиночке, не рассчитывая на соседа (который при половом размножении может просто пропасть)
Я затрудняюсь сказать достаточно ли классического дропаута, чтобы можно было говорить о выявлении фич доступных для интерпретации на конкретном персептроне (скорее всего нет), но работы в этом направлении есть.
>>> Многослойный персептрон с общей функцией распознавания для всей сети, в котором объединены все профили рецепторов. Связь типа все – со всеми.
Есть методы для сжатия DNN, например, вариационный дропаут, который используется в том числе для разрядки нейронных сетей, имеет относительно строгое математическое обоснование на базе баесовской модели и позволяет уйти от принципа "все-со-всеми", итоговые сети сжимаются в десятки раз - то есть по сути реализуется прунинг.
Ты сам понимаешь, я не спец в искусственных нейронных сетях, я осваиваю азы и это должно быть видно, но вопросы о корректности сопоставления искусственных и биологических сетей уже возникают. Создаётся впечатление, что искусственные нейронные сети всё заметнее движутся в сторону их биологического вдохновителя. При этом толкает их туда, как эвристика, так и математика. Может быть, всё дело в том, что проблемный мир одинаковый (сейчас их используют для решения значимых для человека задач и человеческих игр), а может причины более глубокие. Не знаю. |
|
Род: nan - админ Сообщений: 12306 |
>> широко используется "дропаут" ("метод исключения", "метод прореживания"), когда на части обучающей выборки, которая сейчас используется для обучения, часть связей все-со-всеми в выбранных слоях выпадает из вычислений. Это – совершенно не так, как реализуется в природе. Все-со всеми – уже неверное решение. Но даже такая локализация обучения дает гораздо лучший результат, чем обучение сразу всех слоев. В лекции в таблицу сведено то, что отличием искусственные сети и природную реализацию, там много пунктов. Не просто изоляция нейронов при обучении, а определенное взаимодействие соседних нейронов в слове обеспечивает оптимальное качество специализации. При этом нет никакого такого обратного распространения ошибки, что нонсенс на данном уровне специализации. Ты прервал изучение систематизированного изложения в лекциях того, что оптимизировала природа, демонстрируешь очень большое недопонимание этого, но пытается как-то что-то сопоставлять с искусственными сетями, а это – принципиально неверно. |
|
Айк - админ Сообщений: 3768 |
То что отличий очень много, мне очевидно. А вот из чего следуют рассуждения: "как-то что-то сопоставлять с искусственными сетями – принципиально неверно", - непонятно.
Я не думаю, что есть какая-то принципиальная несовместимость, и я буквально с каждым пунктом критических сопоставлений в твоей таблице несогласен. Тут ничего не поделать, видимо. Как мог, я возразил.
>>> Ты прервал изучение систематизированного изложения в лекциях
Да, я в скором времени вернусь к лекциям. Но там для меня нет чего-то принципиально нового, кроме безусловно ценной возможности лучше понятно твои взгляды и повторить любимый материал.
И опять же, часть слушателей твоих лекций легко соглашается с достаточно спорным материалом и смелыми обобщениями. Им всё зашибись. Но я так не умею.
С теми же искусственными нейронными сетями есть много нюансов, множество архитектур - это сложная быстро развивающаяся область машинного обучения, где у станка сейчас работает множество талантливых людей. Если просто так вестись на твои оценки, то можно попасть на огромные деньги и упустить массу возможностей связанных с ML.
Если же забить на твои оценки и думать своей головой, то от твоих материалов гораздо больше пользы. В том числе становится легче понимать искусственные нейронные сети, как минимум, ряд идей в них.
Но в целом, спасибо тебе, что ты нами вообще занимаешься, тратишь на нас время, всё это очень важно и по-человечески ценно. Мне кажется, я тебе не так часто говорю спасибо, как следовало бы.
>>> нет никакого такого обратного распространения ошибки
Я как раз уткнулся носом в работу Хинтона на эту тему: Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures (2018), - он ведущий специалист в искусственных нейронных сетях на сегодня, и как раз исследует биологически правдоподобные альтернативы обратному распространению ошибки, но приходит к выводу, что все они пока работают плохо. |
|
wattsFull Poster Сообщений: 85 |
Я вижу логику различий так , но это гипотеза. Основная цель обучения искусственных сетей - научиться распознавать признаки характеризующие заранее размеченную выборку. Здесь прямая связь с обратным распространением ошибки , как подходом. Критерий удачного обучения - распознавание заранее заданных признаков. Если мы посмотрим на естественную нейросеть - там нету заранее заданного критерия удачного обучения.То есть, что именно из всего что потенциально можно научиться распознавать потребуется в дальнейшем - не известно заранее. И до момента включения механизма "означивания" признаков сеть учится "в слепую"( все выделяемые признаки ничего не значат и равноценны). Раз так , то осмысленным будет задать избыточность (!) в возможности выделять любые признаки. При этом так как количество нейронов все равно ограниченно для живых организмов , то оптимальным кажется выделить в самом начале некоторую универсальную азбуку признаков и по мере надстраивания следующих слоев выделять все более специфические наборы признаков все более контрастировать одни "объекты" от других за счет разницы профилей возбуждения от разных групп распознавателей с нижележащих уровней. Если эта гипотетическая логика верна , то в МЛ с обратным распространением не возникает такой азбуки специализаций нейронов и возможность произвольно выделять группы признаков из всего массива. В то же время мне кажется подобные идеи наверняка могут витать в головах нейропрограммистов. Другое дело что практически они ограничены вычислительной мощностью. Резюмируя мысль - цель природной нейросети - вычленение избыточно большого количества признаков , в том числе это дает потенциальную возможность произвольного выделения вниманием и означивания. Цель искусственных нейросетей - максимально точное распознавание ограниченного количества заранее заданных групп признаков. У меня конечно дофига вопросов к вышенаписанному мною.)Например не очень ясно как зарегулировать количество нейронов в новом слое , что бы их было достаточно.Одно из решений - опять таки избыточность , сделать много и часть проредить. Либо включать новые нейроны в течении некоего срока - он может быть выбран эмпирически как время созревания определенного слоя. |
|
Род: nan - админ Сообщений: 12306 |
В том, что ты озвучил, я тебе дал ответ. Обоснования того, как именно реализовала природа - есть. Если есть желание подробно обсудить и оспорить – заводи тему по различиям.
>>часть слушателей твоих лекций легко соглашается с достаточно спорным материалом и смелыми обобщениями. Им всё зашибись. Но я так не умею. Ты не показал в чем именно спорность. То, кто с чем соглашается или нет – их дело, ты не проводил опрос. Говорим беспредметно, какой смысл в такой огульности?
>> он ведущий специалист в искусственных нейронных сетях на сегодня, и как раз исследует биологически правдоподобные альтернативы обратному распространению ошибки, но приходит к выводу, что все они пока работают плохо. У подобных исследователей пока нет ни малейшего понимания в том, когда и как должна осуществляется коррекция ошибками так, чтобы система стала само-адаптирующейся, а не следовала оценкам задающего оценки эксперта. Это – область личной произвольности оценок. На доосознанном же уровне используется гомеостатическая система значимости в качестве “подкрепления”. |
|
Айк - админ Сообщений: 3768 |
По искусственным нейронным сетям:
>>> (watts) Критерий удачного обучения - распознавание заранее заданных признаков.
Признаки, фичи, можно задать заранее. Но в целом искусственные многослойные нейронные сети самостоятельно ищут фичи.
>>> (watts) Основная цель обучения искусственных сетей - научиться распознавать признаки характеризующие заранее размеченную выборку.
Тут нужно оговориться. Цель - не эффективно распознавать размеченные данные - это элементарная, тривиальная задача, а эффективно работать в предметной области. Для этого сеть должна избежать переобучения.
Способов обучения и задач у нейронных сетей много, в том числе:
- без учителя, с учителем, с подкреплением; - есть распознающие сети (классифицирующие и ранжирующие), есть порождающие сети;
По биологическим:
>>> (watts) Если мы посмотрим на естественную нейросеть - там нету заранее заданного критерия удачного обучения.
Скорее да, чем нет.
>>> (watts) То есть, что именно из всего что потенциально можно научиться распознавать потребуется в дальнейшем - не известно заранее.
Тут нужно оговориться: биологические сети прошли через естественный отбор и обладают ограниченной пластичностью в приделах тех проблемных областей, к которым адаптировались.
При этом иногда биологические модули могут эффективно перестраиваться, кооперироваться для решения новых задач: например, для задач чтения и письма. Но переоценивать пластичность биологических сетей не стоит, равно как недооценивать.
>>> (watts) о момента включения механизма "означивания" признаков сеть учится "в слепую"( все выделяемые признаки ничего не значат и равноценны)
Да. В искусственных сетях есть аналог - обучение без учителя.
>>> (watts) Раз так , то осмысленным будет задать избыточность (!) в возможности выделять любые признаки.
Любые, нет. Что искусственные, что биологические сети ограничены своей внутренней архитектурой.
Выбор архитектуры у искусственных сетей играет большую роль, так как в архитектуре сети (например, свёрточной) заключено специфическое знание о мире, которое подталкивает сеть в нужном направлении. То же самое верно для биологических сетей.
Архитектура биологических сетей обусловлена адаптацией к проблемной среде. Но это не значит, что эта архитектура жестко и однозначно закодирована в геноме. Просто, она не так пластична, как многим кажется.
>>> (watts) При этом так как количество нейронов все равно ограниченно для живых организмов , то оптимальным кажется выделить в самом начале некоторую универсальную азбуку признаков и по мере надстраивания следующих слоев выделять все более специфические наборы признаков все более контрастировать одни "объекты" от других за счет разницы профилей возбуждения от разных групп распознавателей с нижележащих уровней.
Верно. У искусственных сетей тоже самое. Вычислительные мощности стоят дорого, сети часто нужно умещать на мобильниках. Отсюда появляются специальные методы сжатия искусственных нейронных сетей, которые при этом часто улучшают результаты распознавания, как в случае с вариационным дропаутом.
>>> (watts) в МЛ с обратным распространением не возникает такой азбуки специализаций нейронов и возможность произвольно выделять группы признаков из всего массива.
Возникнет. Я выше описал метод дропаута и методики послойного обучения глубоких сетей.
>>> (watts) возможность произвольно выделять группы признаков из всего массива
В ML есть сети с вниманием и рабочей памятью. Они крайне важны для ряда прикладных задач, например, для переводов. Это не прямые аналоги биологического внимания и короткой памяти / рабочей памяти, но тем не менее.
>>> (watts) В то же время мне кажется подобные идеи наверняка могут витать в головах нейропрограммистов.
Не просто витают. Это реализовано. При этом речи о том, что биологические и искусственные нейронные сети эквивалентны - нет. Мы пока очень далеки от понимания важных нюансов работы биологических сетей и их строгого математического осмысления, но в тех моментах, что ты описал, биологические и искусственные сети вполне сопоставимы.
>>> (watts) И до момента включения механизма "означивания" признаков сеть учится "в слепую"( все выделяемые признаки ничего не значат и равноценны).
Посмотри, как работают AlphaGo и AlphaStar. В них используется обучение с подкреплением. Такой способ обучения используется в средах с высокой степенью неопределенности. |
|
Айк - админ Сообщений: 3768 |
>>> (nan) Если есть желание подробно обсудить и оспорить – заводи тему по различиям.
Да, я попозже создам тему. Пока рановато, наверное.
>>> (nan) То, кто с чем соглашается или нет – их дело, ты не проводил опрос. >>> Говорим беспредметно, какой смысл в такой огульности?
Есть довольно много теорий, вроде тех же IIT и GWT, нейродарвинизма и других, которые кажутся тебе поверхностными и далекими от сути происходящего. Ты обычно не тратишь время на чтение статей / литературы по этой тематике. В твоих работах не встретить ни современных философов, ни теоретиков.
Почему?
Ну потому что ты не согласен, как с суждениями авторов, так и просто предпочитаешь делать личные системные обобщения.
Ровно те же эмоции испытываю я, когда читаю твои лекционные материалы, чтобы двигаться дальше по лекциям, мне нужно пересказать в ответах на вопросы твою точку зрения и умолчать о своей.
Иногда, когда есть возможность поделиться своими взглядами, я этим пользуюсь, как в случае с "альтернативной аксиоматикой". Но в случае с искусственными нейронными сетями - это принципиально невозможно выразить в домашней работе. Тем более когда мои личные представления только разрабатываются. В домашнем задании остаётся просто пересказывать тебе твои взгляды, которых я, в общем-то, не разделяю.
Я сейчас в рамках школы ставлю перед собой цель лучше тебя понять. Но понять и согласиться, это не всегда одно и тоже, и это создаёт некоторые сложности. Каких-то ошибок с твоей стороны нет, ты абсолютно корректен и отзывчив в обсуждениях. |
|
wattsFull Poster Сообщений: 85 |
"У искусственных сетей тоже самое. Вычислительные мощности стоят дорого, сети часто нужно умещать на мобильниках. Отсюда появляются специальные методы сжатия искусственных нейронных сетей, которые при этом часто улучшают результаты распознавания, как в случае с вариационным дропаутом." Айк , я не уверен что это - тоже самое. Представь что у тебя есть громадный набор неразмеченных данных.Ты можешь задать сети некоторое правило для формирования связей - навроде правил Хебба.То есть единственным критерием для образования тех или иных связей будет взаимоактивность нейронов.А единственным критерием для выделения признаков - закономерности в данных. Суть алгоритма образований связей, взаимодействуя с закономерностями в данных , - должна выделить специализированные детекторы отражающие эти закономерности. Но "предметное поле" заранее не задано. После завершения специализации каждого слоя из выделенных примитивов можно выделить "предметное поле" значимых признаков. Разница с размеченными данными большая. Если сеть обучается только на размеченных данных , то нет шанса детектировать объекты вне "предметного поля" - для них просто нету специализированных распознавателей. Можно конечно сказать , что предметное поле натуральной нейросети - это все данные которые просто кластеризуются.Можно так сказать? |
|
Айк - админ Сообщений: 3768 |
>>> Если сеть обучается только на размеченных данных , то нет шанса детектировать объекты вне "предметного поля" - для них просто нету специализированных распознавателей.
Ещё немного о дропауте простым языком: http://www.nanonewsnet.ru/articles/2016/kak-obuchaetsya-ii
Как же всё-таки сделать так, чтобы каждый нейрон обучался какому-нибудь полезному признаку? И снова мы возвращаемся к регуляризации. В данном случае речь идет о дропауте (dropout; переводов хороших для этого слова мы не знаем, да и бог с ним). Как мы уже упоминали, обучение нейронной сети обычно производят стохастическим градиентным спуском, случайно выбирая по одному объекту из выборки. Дропаут-регуляризация заключается в том, что при выборе очередного объекта изменяется структура сети: каждая вершина выбрасывается из обучения с некоторой вероятностью. Выбросив, скажем, половину нейронов, мы получим “новую” архитектуру сети.
Проведя обучение на оставшейся половине нейронов, мы увидим очень интересный результат. Теперь каждый нейрон должен обучиться выделять какой-нибудь признак сам. Он не может “рассчитывать” на то, что объединится с другими нейронами, потому что те могут быть выключены.
С дропаутом мы словно усредняем гигантскую смесь разных архитектур: получается, что мы на каждом тестовом примере строим новую модель, на каждом тестовом примере берём одну модель из гигантского ансамбля и обучаем на один шаг, затем для следующего примера берём другую модель и обучаем её на один шаг, а потом в конце на выходе усредняем все эти модели. Это очень простая с виду идея; но оказывается, что дропаут дает очень сильный эффект практически на всех глубоких моделях.
И ещё одно небольшое лирическое отступление, которое свяжет то, что происходит сейчас, с тем, с чего мы начинали. Что делает нейрон при дропауте? У него есть своё значение, это обычно число от 0 до 1 или от —1 до 1. И он его посылает, но не всегда, а с вероятностью ½. Но что если поменять местами эти числа? Пускай теперь нейроны посылают всегда один и тот же по величине сигнал, а именно ½, но с вероятностью, равной своему значению. Средний выход нейрона от этого не изменится, но в результате у нас получатся стохастические нейроны, случайно посылающие сигналы. Интенсивность, с которой они это делают, зависит от их выхода. Чем больше выход, чем более нейрон активирован, тем чаще он будет посылать сигналы. Ничего не напоминает? Мы говорили об этом в самом начале статьи: нейроны в мозге работают именно так. Как и в мозге, нейрон не передает амплитуду спайка, нейроны передают один бит — факт спайка.
Интересно, что с применением дропаута и грамотной инциализации уходит потребность в предобучении (обучении без учителя).
В мозге первичные распознаватели тоже не являются предобученным в строгом смысле слова. На сегодня не вполне понятно, как формируются первичные распознователи, какова регулирующая роль генов и эпигенетических факторов. Известно, например, что при переключении первичных слуховых и визуальных зон у эмбрионов животных (переключении между собой входов в эти зоны) ничего страшного не происходит, вырастают вполне адекватные животные. У таких животных есть некоторые проблемы со зрением и со слухом, но не серьёзные.
То есть так называемое "обучение без учителя" (другое название: "предопределенное обучение" - (c) Марвин Минский) в первичных зонах - это тема для дальнейших исследований. Верно, что в итоге в этих областях распознаются базовые примитивы, но детали того, как происходит формирование этих распознавателей, по-моему, плохо изучены.
Я думаю, что nan меня поправит, т.к. у него скорее всего есть гораздо более качественные представления по этому вопросу. Я сам только разбираюсь.
Опять же, если мы говорим об абстракциях высокого уровня, реальных абстракциях, которые формируются с учётом гомеостаза системы, окрашены личным субъективным опытом, то вполне возможно, что ты не сможешь увидеть принципиально новый объект, если он вдруг окажется в твоём поле зрения. Детекторы "новизна x значимость" просто не сработают.
https://scorcher.ru/neuro/neuro_sys/invisible/invisible2.php - белая слепота.
Это не было бы возможно, если бы сети реально глубоко затачивались под обучающие выборки.
Вот конкретные рекомендации по переобучению предобученных сетей:
Наборы данных похожи, новых данных много.
Наборы данных похожи, новых данных мало.
Наборы данных не похожи, новых данных много.
На сегодня использование предобученных сетей - обычная история. Поскольку обучение искусственных нейронных сетей стоит дорого, становится выгодно дообучать сети, которые уже прошли определенное обучение за счёт крупных компаний, исследовательских институтов.
При этом такие предобученные сети можно использовать не целиком, их можно частично разбирать, то есть работать и (?)дообучать(?) отталкиваясь от разных уровней абстрагирования. Это возможно в том числе благодаря процедуре дропаута, когда мы не даём слою / слоям во время обучения подстраиваться под конкретную архитектуру сетки.
Я думаю, что я на твои возражения смог ответить только частично, но может быть этого достаточно, и ты как-то скорректируешь вопрос, прояснишь его, если посчитаешь нужным. |
|
Род: nan - админ Сообщений: 12306 |
т.е. ты и собственные представления недосформировал и мои не понял (то, что не понял и неверно интерпретируешь – постоянно вылазит), но мои взгляды не разделяешь :) классно. >>В мозге первичные распознаватели тоже не являются предобученным в строгом смысле слова. Вот пример: ты не имеешь сформированного представления, как специализируются нейроны в природной реализации, но делаешь уверенные конечные утверждения. Чего стоят они? >> То есть так называемое "обучение без учителя" (другое название: "предопределенное обучение" - (c) Марвин Минский) в первичных зонах - это тема для дальнейших исследований. Верно, что в итоге в этих областях распознаются базовые примитивы, но детали того, как происходит формирование этих распознавателей, по-моему, плохо изучены. Т ы вообще не в теме, Айк. Нахватался отдельных фрагментов разных авторов и торопишься вынести заключение. >> Я думаю, что nan меня поправит, Я не хочу, чтобы ты здесь продолжал писать здесь в таком стиле. Это – не твой топик. Чтобы тебя поправить, нужно провести очень немалое индивидуальное натаскивание по теме с показом всех материалов, сопоставление и обобщение которых дает однозначную модель. В том числе писать об искусственных нейросетях, которые не имеет никакой корреляции с природными. Это можно сделать в отдельной теме про искусственные сети. Аминь. |
|
Айк - админ Сообщений: 3768 |
Да, хорошо. Наверное, ты прав. Я сделаю тему через пару дней, как смогу переписку продолжить :) Хорошего дня всем :) |
|
wattsFull Poster Сообщений: 85 |
"нет шанса детектировать объекты вне "предметного поля" Айк , все-таки ты меня не убедил.) С одной стороны аналогия с предметным полем понятна и в целом уместна , а с другой стороны чем больше и разнообразнее предметное поле , тем больше промежуточных распознавателей сформируется и в этом отношении обратное распространение смотрится как заведомое ограничение. Я думаю узкая специфичность распознавателей будет типичным багом сетей с обратным распространением (или уже стала и проблемы с переобучением свидетельство тому). Думаю со временем можно будет вернуться к обсуждению этой темы , но пока ничего содержательного добавить не могу.... |
|
Айк - админ Сообщений: 3768 |
>>> Думаю со временем можно будет вернуться к обсуждению этой темы Да, на форуме договорим, как настроение будет. Я пока только разбираюсь в искусственных нейросетях, смотрю лекции и читаю современные учебники. |
|
Айк - админ Сообщений: 3768 |
>>> (watts) Я думаю узкая специфичность распознавателей будет типичным багом сетей с обратным распространением
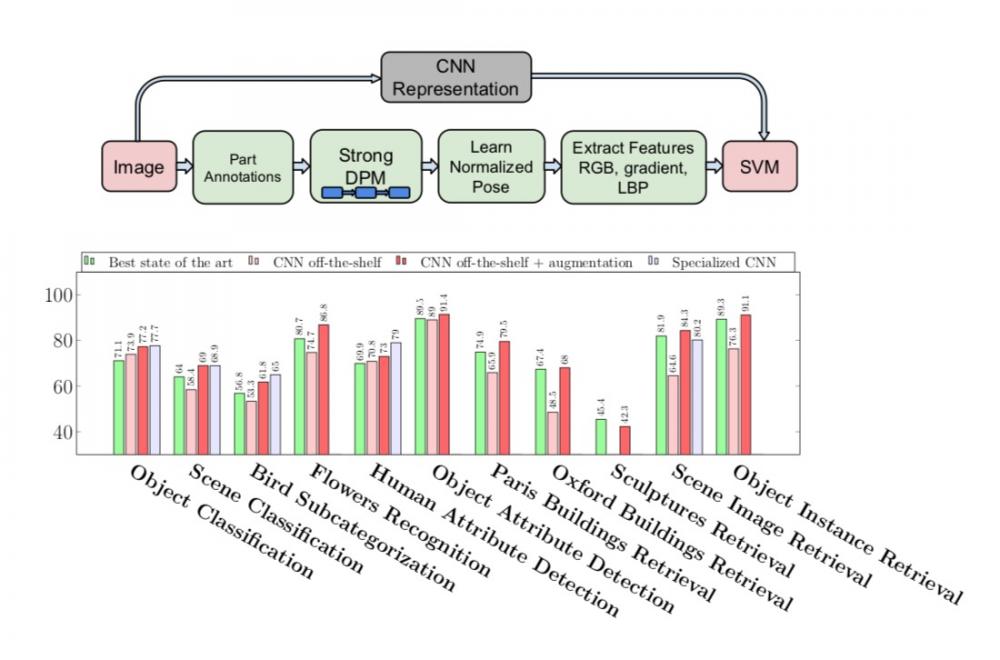
https://arxiv.org/pdf/1403.6382.pdf - 2014, CNN Features off-the-shelf: an Astounding Baseline for Recognition
Recent results indicate that the generic descriptors extracted from the convolutional neural networks are very powerful. This paper adds to the mounting evidence that this is indeed the case.
Вот статья, в которой исследуется transfer learning (перенос обучения) и показано, что фичи натренированные на одном корректно собранном тренировочном множестве потом хорошо переносятся на другие.
Конкретно в этой статье речь о фичах, которые достают с помощью свёрточных сетей (CNN).
|
|
wattsFull Poster Сообщений: 85 |
Айк , в ImageNet около 20000 категорий размечено , можно быть уверенным что выборки не перекрываются ? Цифры тем не менее занятные... |
|
Айк - админ Сообщений: 3768 |
>>> Айк , в ImageNet около 20000 категорий размечено В ImageNet содержатся как общие категории, так и субкатегории для ряда объектов, например, собак.
Этот датасет специально разработан так, чтобы нейросети, которые на нём тренируются, учились делать, как общую категоризацию по объектам, так и разбирались в частностях, обращали внимание на детали. Для этого значительный объем всего датасета составляют породы собак и, например, ящеров, которые могут различаться только деталями кожного покрова.
В 2012 году был прорыв в прохождении этого датасета как раз сетями CNN (сеть AlexNet).
Вот какие фичи выделяет сеть AlexNet на первом свёрточном слое (CNN):
Я думаю, ты согласишься, что эта картина схожа с той, которую наблюдали нобелевские исследователи Хьюбел и Визел в 60-х годах:
То есть твоё рассуждение о том, что современные сети не способны к построению эффективного выразительного языка базовых абстракций (фичей) спорно.
Вот тебе развлечение на день: http://people.csail.mit.edu/torralba/research/drawCNN/drawNet.html - смотри дома на компе. Нажимаешь на любой слой сети и она показывает тебе, что это за нейрон, на какие картинки он активируется больше всего и из каких фичей состоит :)
Предлагаю дальнейшие обсуждения вести на форуме. Нас об этом попросили :)
|
|
Род: nan - админ Сообщений: 12306 |
Перенес все сюда. |
|
wattsFull Poster Сообщений: 85 |
Айк , я начну с книжки Тарика Рашида , там конечно не глубокое обучение , но есть надежда что хоть что-то пойму. Да , тема интереснее чем я думал , но выводы делать пока рано. |
|
Айк - админ Сообщений: 3768 |
Я прочитал несколько книг уже и сейчас смотрю лекции. На мой взгляд, лекции лучше: https://www.youtube.com/channel/UCQj_dwbIydi588xrfjWSL5g/playlists
В книгах, что мне встречались, плохо сбалансирован объём математики и практики. На лекциях лучше объясняют математику и больше практики. Лекции совсем свежие, читает русский специалист, который сейчас работает в сфере ML в США.
Выставляешь в настройках YouTube скорость просмотра x2 и получаешь бодрый динамичный рассказ по теме :)
>>> (nan) Перенес все сюда.
Спасибо! |
|
spiral architectSr. Poster Сообщений: 228 |
Айк, а этот канал: https://www.youtube.com/channel/UCfelJa0QlJWwPEZ6XNbNRyA по сравнению с тем который ты предложил выше лучше/хуже на твой взгляд ? |
|
Айк - админ Сообщений: 3768 |
>>> лучше/хуже на твой взгляд ?
Плюс тех лекций, на которые я дал ссылку, в том, что они сделаны для реальных студентов (преподаватель с ними общается) и сам лектор - практик, который на час отходит от станка, чтобы поделиться опытом, то есть там нет избыточной теории.
Математика в нейросетях сложная и на ней можно застрять. Хотя на деле большая часть реальных работ на нейросетях делается с помощью эвристики (наработки личного опыта) и простых фреймворков типа Keras.
Если ты только-только начал изучать тему и хочешь получить общие представления, то лучше начать с тех лекций, на которые я дал ссылку. Они проще.
Если будет что-то интересное или просто захочется о чём-то поговорить. Пиши сюда. :)
|