Ознакомьтесь с Условиями пребывания на сайте Форнит Игнорирование означет безусловное согласие. СОГЛАСЕН
Книги сайта: «Мировоззрение»,
«Познай себя» , «Основы адаптологии» ,
«Вне привычного» , Лекторий МВАП , «Что такое Я» , «Наука».
Чтобы оставлять сообщения нужно авторизоваться.
Тема форума: «Искусственные нейросети»
1 2
Айк - админ
- админ Сообщений: 3768 !!! личная фото-галерея  Оценок: 4 Оценок: 4список всех сообщений clons Сообщение № 45814 показать отдельно Апрель 22, 2019, 01:18:07 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
nan
- админ Род:  Сообщений: 12229 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 45815 показать отдельно Апрель 22, 2019, 07:17:28 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45792 показать отдельно Апрель 23, 2019, 02:12:18 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
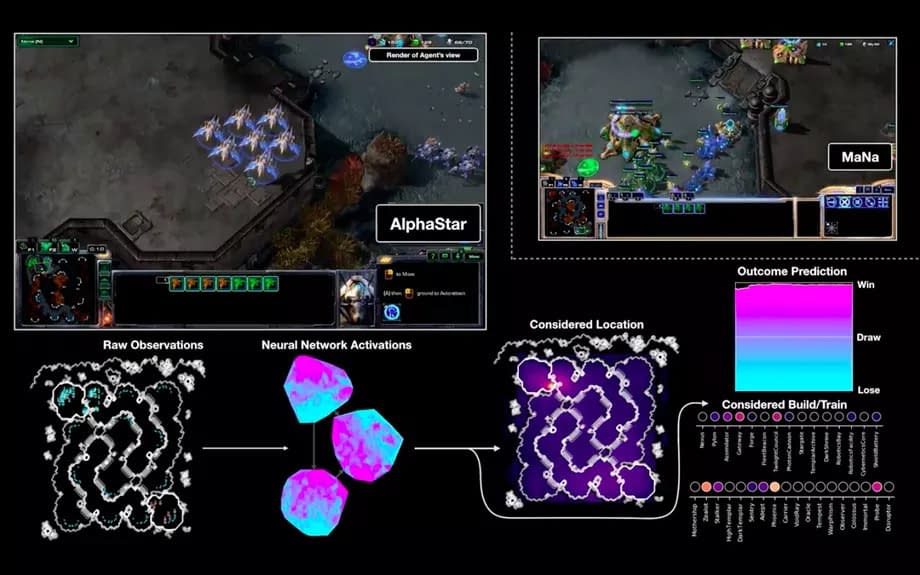
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45793 показать отдельно Апрель 23, 2019, 03:35:16 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
kak
- модератор Род: Сообщений: 771 Телефон: +79217162023 Оценок: 5список всех сообщений clons Сообщение № 45794 показать отдельно Апрель 23, 2019, 07:39:53 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
nan
- админ Род: Сообщений: 12229 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 45795 показать отдельно Апрель 23, 2019, 07:51:16 AM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45796 показать отдельно Июнь 23, 2019, 04:33:45 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
nan
- админ Род: Сообщений: 12229 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 45797 показать отдельно Июнь 23, 2019, 05:15:15 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45798 показать отдельно Июнь 24, 2019, 01:07:20 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
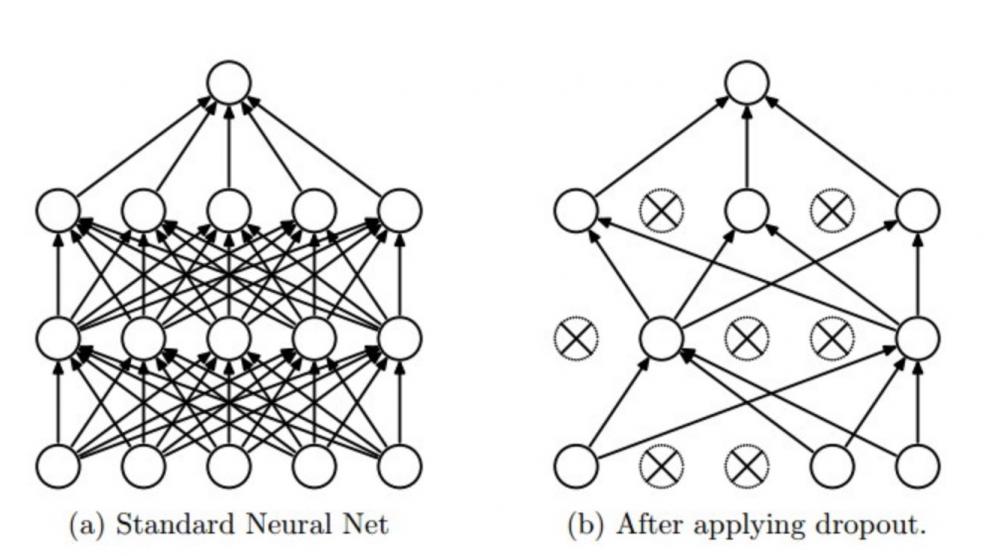
|
nan
- админ Род: Сообщений: 12229 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 45799 показать отдельно Июнь 24, 2019, 08:02:25 AM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45800 показать отдельно Июнь 24, 2019, 12:13:48 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
watts
- unlimited Сообщений: 85 список всех сообщений clons Сообщение № 45801 показать отдельно Июнь 24, 2019, 02:04:51 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
nan
- админ Род: Сообщений: 12229 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 45802 показать отдельно Июнь 24, 2019, 02:25:34 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45803 показать отдельно Июнь 24, 2019, 02:54:39 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
Айк
- админ Сообщений: 3768 !!! личная фото-галерея Оценок: 4список всех сообщений clons Сообщение № 45804 показать отдельно Июнь 24, 2019, 03:07:46 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
Всего Тем: 1923 Всего Сообщений: 47822 Всего Участников: 5155 Последний зарегистрировавшийся: Bambuck
Страница статистики форума | Список пользователей | Список анлимитов
Последняя из новостей:
Страница статистики форума | Список пользователей | Список анлимитов
Схемотехника адаптивных систем - Путь решения проблемы сознания.
Создан синаптический коммутатор с автономной памятью и низким потреблением
Ученые Северо-Западного университета, Бостонского колледжа и Массачусетского технологического института создали новый синаптический транзистор, который имитирует работу синапсов в человеческом мозге.
Тематическая статья: Рефлексы
Рецензия: Статья П.К.Анохина ФИЛОСОФСКИЙ СМЫСЛ ПРОБЛЕМЫ ЕСТЕСТВЕННОГО И ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Пользователи на форуме:Создан синаптический коммутатор с автономной памятью и низким потреблением
Ученые Северо-Западного университета, Бостонского колледжа и Массачусетского технологического института создали новый синаптический транзистор, который имитирует работу синапсов в человеческом мозге.
Тематическая статья: Рефлексы
Рецензия: Статья П.К.Анохина ФИЛОСОФСКИЙ СМЫСЛ ПРОБЛЕМЫ ЕСТЕСТВЕННОГО И ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
| Из коллекции изречений: >>показать еще... |