Первые варианты генетического кода
Относится к разделу Молекулярная биология
От чего зависит способность белков сворачиваться в функционально активную глобулярную структуру?
"Поразительная особенность белков заключается в том, что каждый из них имеет чётко определённую трёхмерную структуру"
[Страер Л. 1984].
"Если принять, что фибриллярные белки эпидермиса, белки кератинизированных тканей, основной белок мышц миозин, а теперь и фибриноген крови - все имеют в основе одну и ту же форму молекулярной структуры и потому, вероятно, представляют собой адаптационные варианты одного исходного принципа, то здесь мы, видимо, столкнулись с одним из великих фактов эволюции биологических молекул".
[K.Bailey, W.T. Astbury, K.M. Rudall Nature 1943]
Биологические макромолекулы, в частности белки и РНК, могут проявлять свои вполне чётко определённые функции только потому, что их структура оргаизована по принципу "всё или ничего". Этот принцип означает, что пространственная структура макромолекул при каком-то диапазоне внешних воздействий "терпит" - сохраняется вместе с функциональными свойствами и лишь потом резко переходит в новую фазу (фазовый переход первого рода), в которой структура меняется, причём часто в виде хаотически организованной молекулы. Все молекулы белка в нативном состоянии идентичны, если не считать флуктуаций структуры, обусловленных тепловым движением атомов в молекуле (существует представление о том, что внитримолекулярная подвижность атомов в белке важна для осуществления молекулой белка определённых функций).
Зададимся вопросом - а всегда ли полипептиды из разных аминокислот будут формировать не случайную, а именно чётко организованную пространственную структуру (такое явление называется фолдингом - сворачиванием)? Оказывается далеко не все случайные последовательности аминокислот способны к самопроизвольному фолдингу. Это - очень важный факт. Даже одна единстенная аминокислотная замена может существенным образом сказаться на эффективности фолдинга или даже совсем его прекратить (полипептидная цепь останестя существовать как денатурированная структура) [Финкельштейн А.В., Птицын О.Б. 2002]. Иногда возможна и промежуточная ситуация, когда только часть белка образует строго определённую структуру, но при этом остаётся конформационно подвижной его некоторая определённая часть. На языке термодинамики это означает, что структурно жёсткие участки изменяют конфорацию с большими энергетическими затратами по сравнению со структурно лабильными участками.
Большинство кодируемых генов белков (отобранных безусловно естественным отбором) в водном растворе могут формировать пространственную структуру самопроизвольно - в первичной структуре белка заложена инфорамация не только о конечной пространственной структуре, но и о последователности этапов самосборки. Однако, даже в этом случае не всегда образованная структура является достаточно стабильной. Мерой стабильности пространственной структуры белка может служить разность свободных энергий нативной и денатурированной форм белка [Кузнецова И.М. и др. 2005]. Если эта величина относительно мала, то белок может и не сформировать стабильной пространственной структуры.
Следует также отметить, что так называемые олигопептиды (которыми обычно называют молекулы с 2-10 аминокислотами) и пептиды (которыми обычно обозначают молекулы с 11-20 аминокислотами) часто в водном растворе не имеют фиксированной конформации и не подвергаются необратимой денатурации.
Кроме того самопроизвольному образованию даже стабильной пространственной структуры может препятствовать достаточно высокая энергии активации, необходимая для достижения нативной структуры белка. Таким образом, далеко не каждая полипептидная цепь может самопроизвольно сформировать стабильную нативную структуру.
Для увеличения стабильности структуры в клетке происходят многочисленные модификации аминокислотных последовательностей - например, образование дисульфидных мостиков между аминокислотами цистеина, которые "сшивают" структуру, делая её прочней.
Немаловажно, что многие полипептиды без специальной помощи со стороны определённых белков сформировали бы хаотические структуры, сходные с денатурированным белком. Эту помощь оказывают особые белки - шапероны. Когда полипептидная цепь только синтезируется на рибосоме, шапероны "удерживают" белки в развернутом состоянии. Шапероны представляют собой обширный класс белков, очень вариабельный по первичной структуре и молекулярной массе. Они способствуют котрансляционному (то есть идущему во время синтеза на рибосоме) сворачиванию. Кроме всего прочего, шапероны отвечают за цис-трансизомеризацию пролина и "правильное" образование дисульфидных мостиков. Связываясь с отдельными участками «опекаемой» ими полипептидной цепи, молекулы так называемого шаперона Hsp70 образуют прочные комплексы, удерживающие цепь в развернутом состоянии. Взаимодействие не является специфическим и в основном реализуется благодаря гидрофобным взаимодействиям. Прочно фиксированная на шаперонах полипептидная цепь не способна к сворачиванию в нативную структуру, так как не обладает необходимой для этого подвижностью. Главная функция Hsp70 состоит в удержании вновь синтезируемых белков от неспецифической агрегации и в их передаче другому «белку-помощнику», шаперонину, роль которого - обеспечить оптимальные условия для эффективного сворачивания.
Наиболее важные элементы вторичной структуры, обеспечивающие эффективный фолдинг, а также структурное и функциональное разнообразие глобулярных белков.
Вспомним кратко, какие существуют основные элементы вторичной структуры белка. К основным элементам вторичной структуры белков относятся (Страер Л. 1984):
1. Правая α-спираль - наиболее распространённый элемент вторичной структуры. Нa каждый виток приходится 3,6 аминокислотного остатка, шаг винта (т.е. минимальное расстояние между двумя эквивалентными точками) составляет 0,54 нм. α-спираль стабилизирована почти линейными водородными связями между NH-группой и СО-группой четвертого по счету аминокислотного остатка. Таким образом, в протяженных спиральных участках каждый аминокислотный остаток принимает участие в формировании двух водородных связей. Нередко конформационно жёсткие участки состоят из 4 или 7 аминокислотных остатков, что соответствует кратности витка спирали [Шатаева Л.К. и др. 2006].
Такого рода структура может нарушаться некоторыми аминокислотами, особенно глицином и пролином.
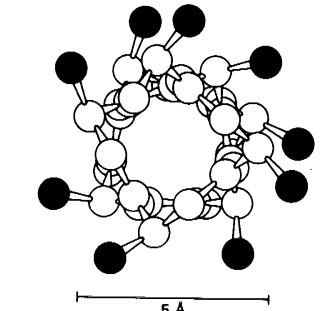
Рис. 1. α-спираль в поперечном разрезе. Боковые цепи находятся снаружи спирали. Рисунок взят из [Страер Л. 1984].
Зеркально-симметричная относительно левая α-спираль встречается в природе крайне редко, хотя энергетически возможна.
2. β-складчатый лист - структура, в которой образуются поперечные межцепочечные водородные связи. Если цепи ориентированы в противоположных направлениях, структура называется антипараллельным складчатым листом - эта структура энергетически более выгодна. Если цепи ориентированы в одном направлении, структура называется параллельным складчатым листом. В складчатых структурах α-С-атомы располагаются на перегибах (см. ), а боковые цепи ориентированы почти перпендикулярно средней плоскости листа, попеременно вверх и вниз.
3. β-петля (или изгиб) образуется в тех участках, где пептидная цепь изгибается достаточно круто, часто находится между β-складчатыми структурами. Этот короткий фрагмент образован обычно четырьмя аминокислотными остаткаами, которые расположены таким образом, что цепь делают реверсивный поворот (на 180о).
Иногда,вместо короткой β-петли из четырёх аминокислот образуется более длинная случайная петля (см. рис. 2).
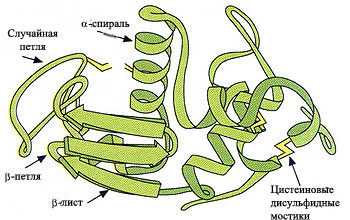
Рис. 2. Основные элементы вторичной структуры белка.
Наиболее важные свойства аминокислот, обеспечивающие структурное и функциональное разнообразие глобулярных белков.
Такие важнейшие физико-химические свойства отдельных аминокислот, как их кислотность, основность, полярность-неполярность, были приведены в таблице 6 в статье Свойства генетического кода - след его возникновения.
Теперь рассмотрим, какие именно аминокислоты имеют предпочтения к формированию тех или иных элементов вторичной структуры.
Мерой этой величины может служить относительная частота встречаемости этих аминокислот в тех или иных элементах вторичной структуры, которая приведена в [Berg et al. 2002, стр. 123-124]:
| Аминокислота | α-спираль | β-складки | β-петля |
| Ala | 1,29 | 0,9 | 0,78 |
| Cys | 1,11 | 0,74 | 0,80 |
| Leu | 1,30 | 1,02 | 0,59 |
| Met | 1,47 | 0,97 | 0,39 |
| Glu | 1,44 | 0,75 | 1,00 |
| Gln | 1,27 | 0,80 | 0,97 |
| Hys | 1,22 | 1,08 | 0,69 |
| Lys | 1,23 | 0,77 | 0,96 |
| Val | 0,91 | 1,49 | 0,47 |
| Ile | 0,97 | 1,45 | 0,51 |
| Phe | 1,07 | 1,32 | 0,58 |
| Tyr | 0,72 | 1,25 | 1,05 |
| Trp | 0,99 | 1,14 | 0,75 |
| Thr | 0,82 | 1,21 | 1,03 |
| Gly | 0,56 | 0,92 | 1,64 |
| Ser | 0,82 | 0,95 | 1,33 |
| Asp | 1,04 | 0,72 | 1,41 |
| Asn | 0,90 | 0,76 | 1,28 |
| Pro | 0,52 | 0,64 | 1,91 |
| Arg | 0,96 | 0,99 | 0,99 |
Здесь аминокислоты сгруппированы согласно их предпочтению к формированию той или иной струтуры. Аргинин не показывает явного предпочтения к одной определённой структуре.
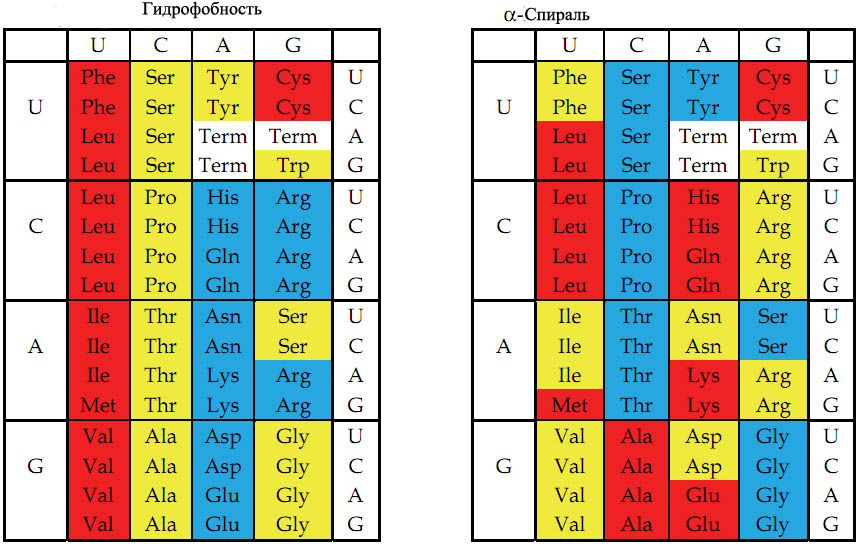
Рис. 3. Цветовое представление физико-химических свойств аминокислот, основанное на значениях, описанных в кн книге Стайера "Биохимия" [Berg et al. 2002, стр. 123-124].
Слева - гидрофобность аминокислот. (о способах измерения гидрофобности см. приложение внизу). Гидрофобность отражает тенденцию неполярных молекул и химических групп растворяться в неполярных растроворителях, что обратно коррелирует со способностью растворяться в воде. Мерой гидрофобности вещества принято считать его коэффициент распределения между органическим растворителем и водой. Довольно детальная систематизация гидрофобно-гидрофильных свойств принадлежит Ганшу [Leo A. et al. 1971], применявшего в качестве неполярного растворителя октанол. Самой гидрофильной аминокислотой является глицин.
Справа - способность аминокислот к формированию α-спирали в белке. Красный, жёлтый и голубой цвета обозначают аминокислоты с большой, средней и малой гидрофобностью (слева) или соответствующей степенью способности к формированию альфа-спирали (справа).
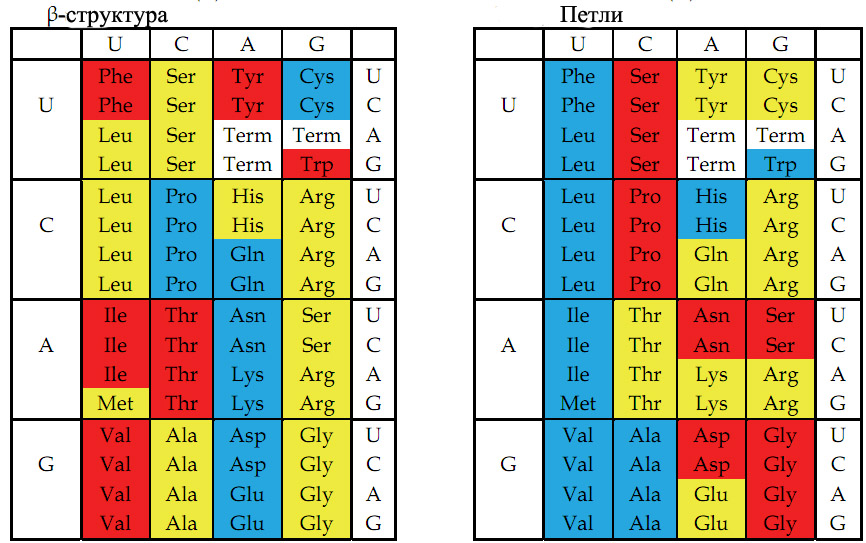
Рис. 4. Цветовое представление физико-химических свойств аминокислот, основанное на значениях, описанных в книге Стайерса "Биохимия" [Berg et al. 2002, стр. 123-124]. Слева - способность аминокислот к образованию β-складчатых структур. Справа - способность аминокислот к формированию коротких четырёхаминокислотных β-петель и более длинных петель. Красный, жёлтый и голубой цвета обозначают аминокислоты с большой, средней и малой способностью к образованию β-складчатых структур (слева) или соответствующей степенью способности к формированию β-петель и более длинных петель (справа).
Из данных, представленных на рисунках 3 и 4 данной статьи, равно как и таблицы 6 из статьи Свойства генетического кода - след его возникновения, видно, что кодоны, кодирующие аминокислоты со сходными гидрофобностями, а также со сходными способностями к формированию различных вторичных структур белка, располагаются блоками.
Как образуются новые гены.
До настоящего времени наиболее популярными являются две взаимодополняющие теории образования новых генов. В первой - теории дупликации генов [Ohno S. 1970] - предсказывается, что после дупликации гена одна копия может приобретать новые функции, тогда как другая - сохраняет старые (рис. 5 А). Согласно второй - теории перетасовки экзонов [Gilbert W. et al. 1997] - новые функциональные гены создаются в результате перетасовки экзонов нескольких генов (рис. 5 В).
На основе каталитических свойств и сходства структур белки принято классифицировать на семейства и суперсемейства. Сами белковые семейства представлены белками со сходными аминокислотными последовательностями и сходными свойствами, тогда как суперсемейства содержат белки со сходными аминокислотными последовательностями, но разными каталитическими свойствами.
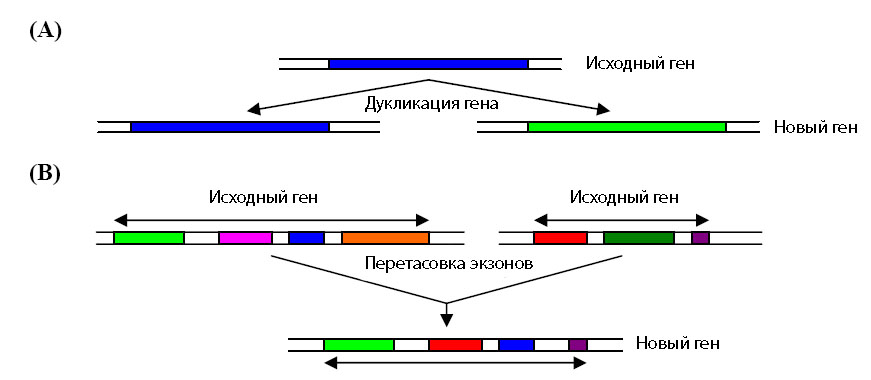
Рис. 5. Иллюстрация к двум теориям образования новых генов. (А) - образование генов через дупликацию. (В) - теория перетасовки экзонов. Рисунок взят из [Ikehara K. 2005] с небольшими изменениями.
Однако обе эти хорошо взаимодополняющие теории не могут объяснить возникновение новых "исходных предковых генов", дающих начало новым суперсемействам белков (рис. 2).
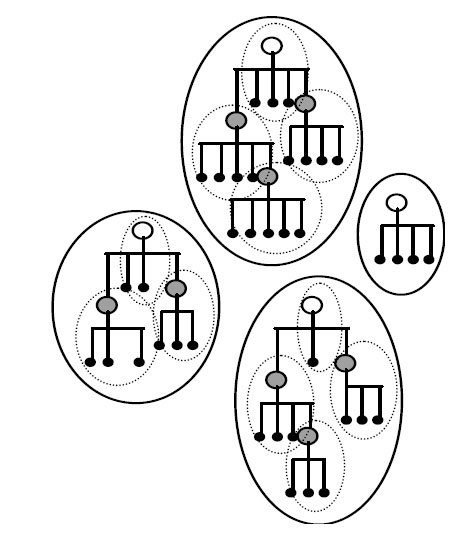
Рис. 6. Отдельные белки (малые чёрные точки) одного суперсемейства могут быть образованы из "исходных предковых генов" для данного суперсемейства (незакрашенные кружки) и происходящих от них "исходных генов" (серые кружки) для данного конкретного семейства. Большие эллипсоиды и малые эллипсоиды обозначают суперсемейства и семейства белков, соответственно. Рисунок взят из [Ikehara K. 2005] с небольшими изменениями.
Модель образования генов для новых белковых суперсемейств - "исходных предковых генов" (“original ancestor genes”).
На основе анализа прокариотных геномов К. Икехара с соавт. [Ikehara K. 2005]. предложили новую модель образования исходных предковых генов из антисмысловых (комплементарных) последовательностей ДНК GC-богатых генов (то есть генов с высоким содержанием нуклеотидов G и C).
Сам GC-состав генов микроорганизмов варьирует в очень широких пределах - от 20 до 75%. В настоящее время считается обоснованной точка зрения, согласно которой для каждой группы микроорганизмов существует давление отбора, которое стабилизирует GC-состав последовательностей ДНК на вполне определённом диапазоне значений для определённой таксономической группы [Sueoka N. 1988].
Для того, чтобы аминокислотная последовательность могла свернуться в водорастворимый функциональный глобулярный белок необходим определённый минимальный набор структурных свойств, их которых главными являются шесть: наличие гидрофобных, кислых и основных аминокислот, наличие аминокислот, дающих возможность формировать α-спираль, β-складчат ые структуры и β- петли [Ikehara K., Yoshida Y. 1998; Ikehara K. 2002, 2005,2009; Ikehara K et al. 1996,2002].
На основе анализа последовательностей 7 прокариотных геномов К. Икехара показали, что свойства современного универсального ГК обеспечивают широкую вариабельность GC-состава геномов: доля аминокислот, обеспечивающих все эти шесть свойств практически не коррелирует с GC-составом генов.
Этот факт является нетривиальным, особенно, если учитывать следующий факт:
У половины аминокислот их доля содержания в белке заметно коррелирует с GC-составом кодирующих их генов.
Статистический анализ показывает, что существует корреляция между GC-составом генов и процентным содержанием отдельных аминокислот. Для одних аминокислот эта корреляция положительная, например, для аланина, тогда как для других - отрицательная, например, для лизина. Примеры, демонстрирующие эти корреляции, приведены на рис. 4.
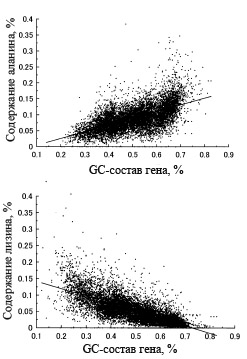
Рис. 4. Зависимости процентного содержания аланина и лизина в белке от GC-состава кодирующих эти белки генов. Каждая точка означает отдельный ген. Рисунок взять из [Ikehara K. 2002]. Графики получены на основе геномных данных для 5 эубактерий и 2 архей с существенно различным средним GC-составом геномной ДНК: Mycobacterium tuberculosis (65,6), Aeropyrum pernix (56,3), Escherichia coli (50,8), Bacillus subtilis (43,5), Haemophilus influenzae (38,1), Methanococcus genitarium (31,3) и Borrelia burgdorferi (28,2) где в круглых скобках приводится средний GC-состав геномной ДНК данного организма.
Как показал корреляционный анализ этих зависимостей, все аминокислоты можно разбить на три группы: без достоверной корреляции с GC-составом генов (соответствующие столбцы заштрихованы серым), с достоверной положительной корреляцией с GC-составом (не заштрихованы) и с достоверной отрицательной корреляцией (закрашены чёрным).
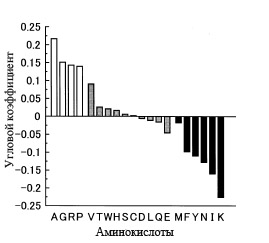
Рис. 5. Наклон (точнее тангенс угла наклона) аппроксимированной линии, полученной для каждой аминокислоты на основе диаграмм, аналогичных таковым, изображённым на рис. 4. Рисунок взять из [Ikehara K. 2002]. Каждая аминокислота обозначена с помощью однобуквенного кода, который детально описан в приложении к данной статьи. Все аминокислоты можно разбить на три группы: без достоверной корреляции с GC-составом генов (соответствующие столбцы заштрихованы серым), с достоверной положительной корреляцией с GC-составом (не заштрихованы) и с достоверной отрицательной корреляцией (закрашены чёрным).
Таким образом, полученные факты говорят о том, что для значительной части аминокислот частота их встречаемости существенно коррелирует с GC-составом генов, тогда как доля аминокислот с шестью ключевыми свойствами для формирования функциональных глобулярных белков - никак не коррелирует с GC-составом.
Так откуда же могут взяться принципиально новые гены - основатели новых суперсемейств?
Возвращаемся к вопросу об образовании принципиально новых генов. К. Икехара с соавторами рассмотрели возможность образования новых генов их той же самой последовательности ДНК, на которой кодировались старые гены. Как это возможно? Это возможно, во-первых, благодаря сдвигу рамки считывания генов (кстати есть гены, которые кодируются одной последовательностью ДНК или РНК, но разными рамками считывания). Поскольку ГК код триплетен но на смысловой цепи возможно дополнительно две новых рамки считывания. Кроме того, новый ген может кодироваться и на комплементарной (антисмысловой) цепи ДНК - причём во всех трёх возможных рамках считывания. Итого получается всего 5 различных вариантов образования принципиально нового гена на основе последовательности уже имеющегося.
Икехара К. с соавторами проанализировали последовательности всех генов в 7 полных геномов прокариот и обнаружили удивительный факт. при высоком GC-составе генов (65~75%) их комплементарная цепь в той же рамке считывания, что и смысловая с высокой вероятностью способна кодировать водорастворимый глобулярный белок с той средней частотой встречаемости аминокислот, способных формировать необходимые пространственные структуры и необходимый минимум для проявления каталитических свойств (наличие, гидрофобных, кислых и основных аминокислот), что и смысловая цепь.
Оказалось, что при высоком содержании GC-нуклеотидов, смысловая и антисмысловая цепи проявляют статистически достоверную триплетную периодичность - чередование нуклеотидов в виде SNS-последовательности (рис. 6).
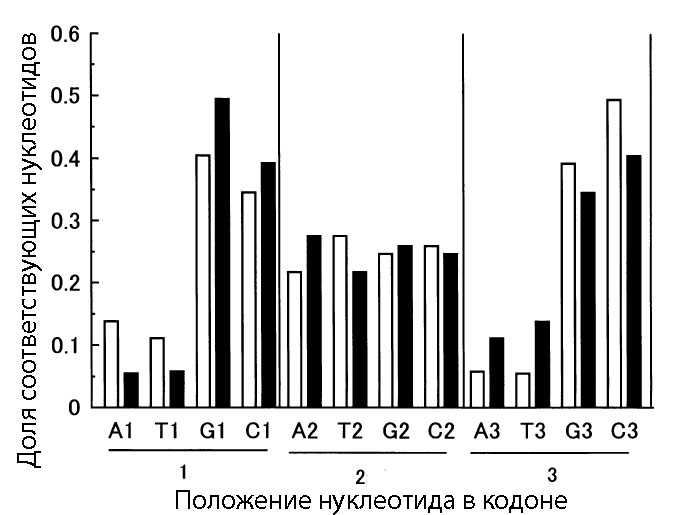
Рис. 6. Средняя доля каждого из азотистых оснований (A - аденина, G - гуанина, C - цитозина, T - тимина) в кодирующих последовательностях генов (незакрашенные столбцы) и в антисмысловых последовательностях (чёрные столбцы). Номер возле нуклеотида обозначает, к какой позиции в кодона (или гипотетических кодонов на антисмысловой цепи) он относится (например, А1 означает аденин в первой позиции кодонов). Данные взяты на основе анализа генов из GC-богатой последовательности генома Pseudomonas aeruginosa.
Кроме того, что немаловажно, при высоком содержании GC-нуклеотидов в гене становится достаточно низкой вероятность встречи одного из трёх стоп-кодонов, которая будет весма высокой при АТ-богатости последовательности гена, а, значит, и вероятность получить достаточно длинный полипептид, способный к проявлению функциональных свойств.
В статье Размеры геномов в РНКовом мире и мутационный фон уже кратко приводился факт доказательства того, что два ключевых суперсемейства белков - АРСазы классов I и II - сформировались на комплементарных последовательностях генов. Учитывая обсуждаемую в данной статье непременную особенность геномов в древнем РНК-мире - максимально возможную компактность генома - становится уместной модель кодирования многих ключевых белков в РНК-белковом мире именно на комплементарных цепях РНК.
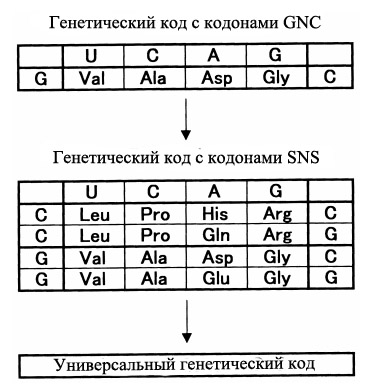
Модель GC-богатых первых генов c SNS-периодичностью как раз хорошо соответствует данному исходному предположению. Кроме того, в рамках данной модели становится уместным предположение о том, что самые первые аминокислоты как раз и должны были кодироваться кодонами с общей формулой SNS. Оказалось, что этому минимальному набору требований удовлетворяет список из 10 аминокислот, которые кодируются универсальной последовательностью SNS, где S - G или C, N - любой нуклеотид (рис. 7). Данное предположение выдвигает в качестве наиболее древних аминокислот в формирующемся генетическом коде 10 аминокислот: глицин, аланин, валин, глутамат, глутамин (возможно появившегося позднее из глутамата), аспартата, валина, пролина и аргинина (или его предковой формы - аминокислоты орнитина - см. Древний дублетный генетический код был предопределён путями биосинтеза аминокислот).
 и
и
Рис. 7. Предполагаемая последовательное появление 4-кодонового ГК с 4 кодируемыми аминокислотами (GNC-код), 16-кодонового SNS-кода (10 аминокислот) и современного 64-кодонового универсального ГК.
Если же список минимальных требований сузить до 4, то останутся только четыре аминокислоты - глицин, аланин, аспартат, валин, обозначаемые в однобуквенном коде (см. приложение внизу) как "G", "A", "D" и "V", соответственно. Поэтому модель возникновения ГК через стадию GNC-кодонов получила также название "[GADV]-теория", а полипептиды, образованные из этих первых аминокислот получили название "[GADV]-полипептиды". Эти 4 аминокислоты обеспечивают четыре из шести условий для формирования достаточно разнообразных структурных и каталитических свойств полипептидов - гидрофобность, способность к образованию α-спирали, β-складки и изгибов.
В связи с этим очень примечательным становится тот факт, что ни одно другое множество кодонов с общей приставкой (первым нуклеотидом кодона) или общим корнем (вторым нуклеотидом кодона) - то есть ни одно другое множество из 4 аминокислот, расположенных в таблице ГК в одном столбце или в одной строчке не обеспечивает такого же разнообразия свойств белков. Исключением является множество аминокислот, кодируемых группой кодонов GNG, содержащее близкое по составу множество аминокислот - Gly, Val, Ala, однако вместо Asp содержит биосинтетически более сложный, а потому и менее вероятный Gln.
В свете данного рассмотрения уместно вспомнить, что наряду с данными 4 аминокислотами наличие серина, а также неканонических α-аминомасляной и α-аминоизомасляной кислот стабильно воспроизводится модельных экспериментах по абиогенному синтезу аминокислот [Ring D. et al. 1972], а также обнаружено в метеоритах [Brinton K.L. et al. 1998]. Почему же эти аминокислоты не вошли в примитивный GNC-код? Этот вопрос интересно рассмотреть с точки зрения минимальных требований для формирования разнообразных полипептидных структур. Серин является малой гидрофильной аминокислотой с высокой способностью формировать изгибы/петли, наподобие глицина. α-аминомасляная кислота подобно аланину имеет неразветвлённую боковую цепь и способна формировать α-спираль. Однако Глицин и аланин являются существенно более простыми и потенциально должны существенно легче синтезироваться для использования в примитивном ГК, чем серин и α-аминомасляная кислота, соответственно. Кроме того, α-аминомасляная кислота является ахиральной с двумя метильными группами, соединёнными с α-углеродным атомом. Можно предположить, что в условиях уже предварительно сформировавшегося архаичного метаболизма использование именно ахиральной молекулы оказалось менее предпочтительным для образования более регулярной и стабильной структуры, так как хиральность аминокислот сама по себе является фактором, способствующим образованию стабильных конформаций в полипептидах. Кроме того, благодаря меньшему размеру глицин способен более жёстко фиксировать изгиб, делая конфорацию полипептида более стабильной.
Об удивительной самосогласованности различных моделей.
Особенно примечательным выглядит также тот факт, что все эти 4 аминокислоты в модельных экспериментах по моделированию абиогенного синтеза аминокислот синтезируются по сравнению с другими каноническими аминокислотами в наибольших концентрациях [Miller S.L. 1986]. Этот факт становится тем более примечательным, что именно для этих аминокислот и как раз для данной группы кодонов обнаружен протокодоновый след в акцепторном стебле тРНК (см. Верхняя половина тРНК более древняя. Протокодоны и первые аминокислоты в древнем пептидном синтезе). Таким образом, авторы модели GNC-SNS-кодов пришли к множеству первых кодонов в древнем ГК независимо от авторов модели образования протокодонового следа в тРНК.
Немаловажным фактом также является требование GC-богатости первых РНК-матриц, так как именно высокое содеражние GC-нуклеотидов обеспечивает более высокую точность воспроизведения РНК [Эйген М., Шустер П. 1982]. Поэтому обе эти модели становятся ещё более убедительными в свете другой обоснованной модели - в РНК- и РНК-белковом мире очень существенная проблема компактности генома обеспечила предпочтение именно для GC-богатых последовательностей РНК, обеспечивающих более точное воспроизведение, а также использование обеих цепей РНК для кодирования тРНК и белков.
И, наконец, очень примечательным является согласование представленной модели первых архаичных вариантов ГК с моделью кодирования не только тРНК, но и генов именно на комплементарных цепях РНК (см. Древние тРНК с комплементарными антикодонами кодировались комплементарными РНК-парами). Нетрудно увидеть, что модели GNC-SNS-кодов, как раз предусматривают возможность такого кодирования.
Возвращаемся вновь к метаболизму, возникшему до появления первых полимерных генов.
Икехара К с соавт. предположили, что в условиях первичного метаболизма до появления генов была возможна квазислучайная полимеризация первых аминокислот генетического кода - глицина, аланина, валина и аспартата. Эксперименты с [GADV]-полипептидами показали, что такого рода квазислучайные полипептиды способны к катализу обратимой реакции гидролизу/образованию пептидной связи, в частности в условиях периодического нагревания-высушивания [Oba T. et al. 2005].
Здесь важно отметить, что реакция протеолиза является обратимой: именно поэтому многие протеазы могут участвовать в образовании пептидной связи. Образование такого рода нерибосомных белков в настоящее время интенсивно изучается как в живых клетках, так и используется для искусстенного нерибосомного синтеза полипептидов с помощью природных протеаз [Антонов В.К. 1983; Stepanov V.M.1996; Sewald N., Jakubke H.-D. 2002].
Этот эмпирический факт даёт основание предположить, что [GADV]-полипептиды могли существовать как псевдореплицирующиеся единицы до формирования первых (GNC)n-генов, благодаря простому аминокислотному составу и высокой каталитической активности. Процесс псевдорепликации подразумевает. что белки имели сходный аминокслотный состав со сходными, но не идентичными структурами. Такого рода полипептиды имеют существенно более простую структуру по сравнению с олиго-РНК-миром и могли им предшествовать как важные каталитические компоненты для образования РНК-белкового мира.
Кроме того, образование первых кодирующих РНК-генов могло произойти в отсутствие белковой РНК репликазы как более примитивный процесс полимеризации GNC-олигонуклеотидов. Данное предположение является одним из вариантов гипотезы А.С. Спирина, который, учитывая проблематичность матричного воспроизведения РНК без белковых молекулы, предположил, что образование более крупных молекул РНК возможно не через матричную полимеризацию, а через последовательные этапы лигирования - сшивки меньших по размеру РНК-блоков, что как раз успешно может катализироваться рибозимами (РНК-лигирование): "...постулируется, что абиогенно синтезируемые олигорибонуклеотиды активно рекомбинировали посредством механизма спонтанной неэнзиматической трансэстерификации, приводя к образованию удлиненных цепей РНК и давая начало их многообразию. Именно этим путем в популяции олигонуклеотидов и полинуклеотидов и могли появиться как каталитически активные виды РНК (рибозимы), так и другие виды РНК со специализированными функциями... Более того, неэнзиматическая рекомбинация олигонуклеотидов, комплементарно связывающихся с полинуклеотидной матрицей, могла обеспечить сшивание (сплайсинг) фрагментов, комплементарных этой матрице, в единую цепь. Именно таким способом, а не катализируемой полимеризацией мононуклеотидов, могло осуществляться первичные копирование (размножение) РНК." (См. ). Существенным аргументом в пользу данного предположения является также успешная иллюстрация возможности саморепликации системы из пула полирибонуклеотидов не из мономеров, а из более коротких молекул, как это было показано, например, в опытах Линкольн и Джойса [].
Наличие [GADV]-полипептидов могло лишь способствовать большему разнообразию каталитической активности, а возникновение GNC-кода обеспечило обратную связь с синтезом этих полипептидов. Другими словами, произошло "взятие под контроль" изначально квазислучайного синтеза [GADV]-полипептидов, структура которых становилась всё более определённой, а потому такие ЖС станвились более конкурентноспособными.
Появление кодируемого белкового синтеза сделало возможным образование не только белковых АРСаз, но и первых РНК-полимераз, на основе которых и сформировался последний универсальный общий предок.
РЕЗЮМЕ
1. В РНК-белковом мире высокое содержание нуклеотидов GC (65~75%) обеспечивало не только актуальное снижение мутабильности при репликации РНК, но и также предпосылки для компактности генома - возможности кодирования на комплементарных последовательностях РНК.
2. GC-богатые последовательности РНК, обладающие SNS-периодичностью, обеспечивали наличие ключевых свойств в кодируемых на обеих комплементарных цепях белках - наличие аминокислот, способных к формированию α-спирали, β-складчатых структур , β-изгиба, наличие гидрофобных, кислых и основных аминокислот.
3.GNC и SNS-периодичности могли обеспечивать защиту от сдвига рамки считывания в условиях примитивного трансляционного аппарата в РНК-белковом мире.
4. Первые полипептиды в ЖС были представлены преимущественно четырьмя аминокислотами: глицином, аланином, валином и аспартатом, которые были способны образовывать водорастворимые глобулярные белки с каталитическими активностями, обеспечивавшими гидролиз/образование пептидной связи. Эти так называемые [GADV]-полипептиды образовали квазиреплицирующиеся структуры, являющиеся компонентами древнего метаболизма.
5. Регулярное образование первых квазистабильных полимерных РНК вероятно обеспечивалось не матричной полимеризацией, а серией последовательных лигировний-сшивок более мелких фрагментов с регулярной (GNC)n-структурой.
6. Фомировние обратной связи между синтезом регулярных (GNC)n-структур [GADV]-полипептидов привело к образованию первого примитивного кодируемого пептидного синтеза. "Взятие под контроль" изначально квазислучайного синтеза полипептидов, структура которых становилась всё более определённой, обеспечило большую конкурентноспособность примитивных живых систем и способствовало дальнейшей эволюции генетического кода.
ЛИТЕРАТУРА
Антонов В.К. Химия протеолиза. // Москва. Наука. 1983. С.135-147.
Кольман Я., Рём К.-Г. Наглядная биохимия. Мир, 2004 г. Твердый переплет, 469 стр.
Кузнецова И.М., Форже В., Туроверов К.К. . // Цитология. 2005. Т.47. №11. С.943-952.
Спирин А.С. .
Страер Л. Биохимия. Т.1, Москва, "Мир", 1984.
Финкельштейн А.В., Птицын О.Б. Физика белка. М: Книжный дом "Унивеситет". 2002. 376 с.
Шатаева Л.К., Хавинсон В. X., Ряднова И. Ю. / Санкт-Петербург, "Наука", 2003.
Эйген М., Шустер П. Гиперцикл. Принципы самоорганизации макромолекул. Москва, "Мир", 1982.
Berg J.M., Tymoczko J.L., & Stryer L. 5th ed. New York: W. H. Freeman and Company. 2002.
Brinton K.L., Engrand C., Glavin D.P., Bada, J.L., Maurette M. A search for extraterrestrial amino acids in carbonaceous Antarctic micrometeorites. // Orig. Life Evol. Biosph. 1998. V.28. P.413-424.
Gilbert W., de Souza S. J., Long M. Origins of genes. // Proc. Natl. Acad. Sci. USA (1997. V.94. P.7698-7703 .
Ikehara K. . November 2011
Ikehara K. // J. Biol. Macromol. 2005. V.5. P.21-30.
Ikehara K. . // J. Biosci. 2002. V.27. P.165-186.
Ikehara K. Possible steps to the emergence of life: The [GADV]-protein world hypothesis. // Chem. Record. 2005. V.5. P.107-118.
Ikehara K. Pseudo-replication of [GADV]-proteins and origin of life. // Int. J. Mol. Sci. 2009. (International Journal of Molecular Sciences) . V.10. P.1525-1537.
Ikehara K., Amada F., Yoshida S., Mikata Y., Tanaka A. A possible origin of newly-born bacterial genes: significance of GC-rich nonstop frame on antisense strand. // Nucl. Acids Res. 1996. V.24. P.4249-4255.
Ikehara K., Omori Y., Arai, R., Hirose A. A novel theory on the origin of the genetic code: a GNC-SNS hypothesis. J. Mol. Evol. 2002. V.54. P.530-538.
Ikehara K., Yoshida Y. SNS hypothesis on the origin of the genetic code. Viva Origino. 1998. V.26. P.301-310.
Leo A., Hansch C, Elkins D. Partition coefficients and their uses // Chem. Revs. - 1971. - N.6. - P.525-616.
Lincoln T.A., Joyce G.F. // Science. - 2009. - V.323. - P.1229–1232.
Miller S.L. Current status of the prebiotic synthesis of small molecules. // Chem. Scr. 1986. V.26B. P.361-368.
Oba T., Fukushima J. Maruyama M. Iwamoto R. Ikehara K. Catalytic activities of [GADV]-petides. // Ori. Life Evol. Bioshph. 2005. V.35. P.447-460.
Ohno S. Evolution by gene duplication. / Springer Heiderberg. 1970.
Ring D., Wolman Y., Friedmann N., Miller S.L. Prebiotic synthesis of hydrophobic and protein amino acids. // Proc. Natl. Acad. Sci. USA. 1972. V.69. P.765-768.
Sewald N., Jakubke H.-D. Copyright © 2002 Wiley-VCH Verlag GmbH & Co. KGaA
ISBNs: 3-527-30405-3.
Stepanov V.M. Proteinases as catalysts in peptide synthesis. // Pure & Appl. Chem. - 1996. - V.68. - P.1335-1339.
Sueoka N Directional mutation pressure and neutral molecular evolution. // Proc. Natl. Acad. Sci. USA. 1988. V.85. P.2653-2657.
Tracey A. Lincoln, Gerald F. Joyce. Self-Sustained Replication of an RNA Enzyme // Science. Published online January 8, 2009.
ПРИЛОЖЕНИЕ
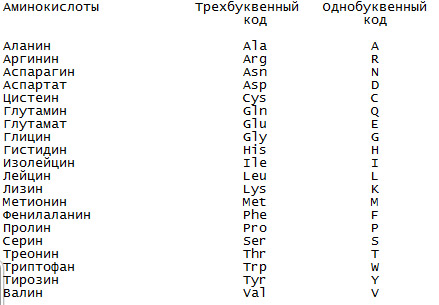
Однобуквенный и трёхбуквенный коды, используемые для обозначения аминокислот.
Для обозначения аминокислот в белке обычно используются два вида обозначений: с помощью трёх букв (трёхбуквенный код) и с помощью одной буквы (однобуквенный код).
Статьи, связанные с темой
Верхняя половина тРНК более древняя. Протокодоны и первые аминокислоты в древнем пептидном синтезе
Древние тРНК с комплементарными антикодонами кодировались комплементарными РНК-парами.
Размеры геномов в РНКовом мире и мутационный фон
Список публикаций >>